Table of Contents
Introduction
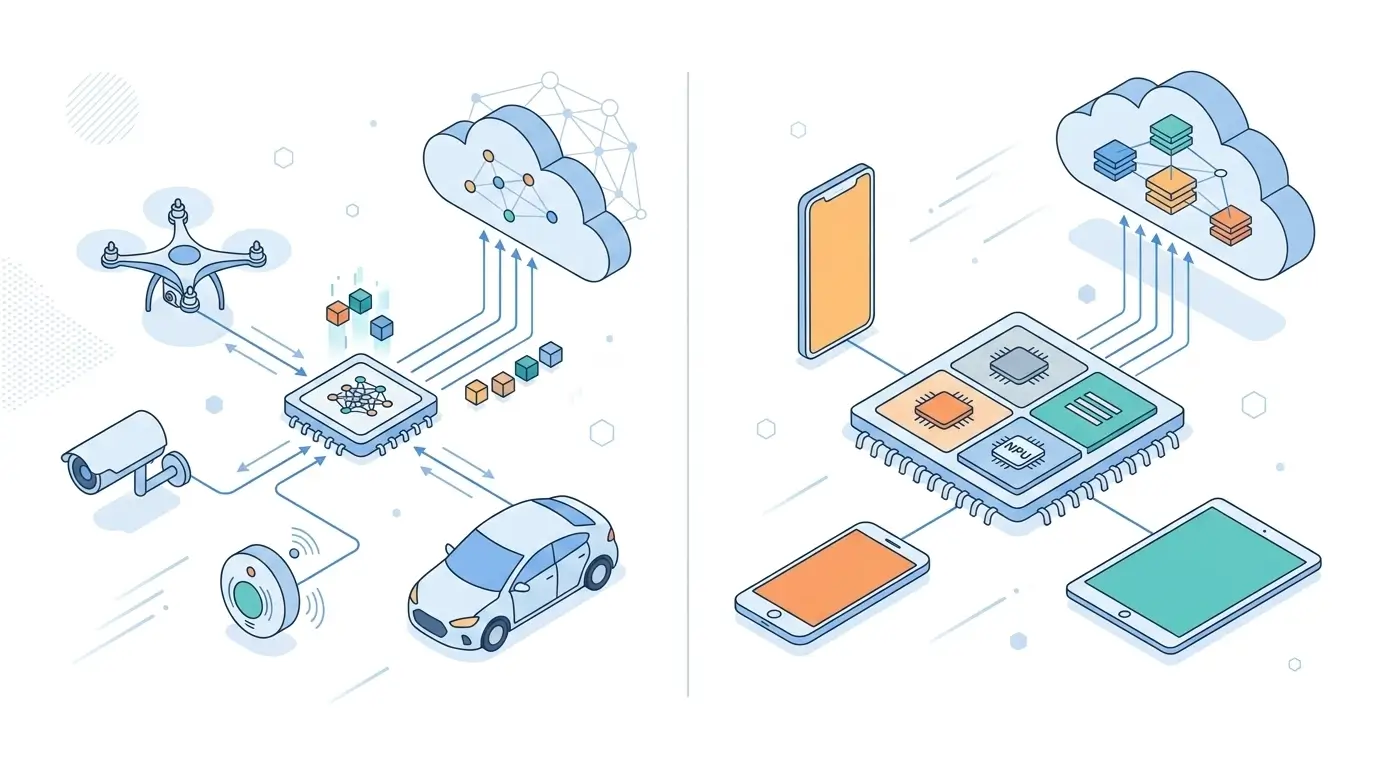
AI phone cloud dependency exists because smartphones are power-limited edge devices, while advanced AI models require datacenter-scale memory and sustained compute. Modern AI smartphones integrate specialized Neural Processing Units (NPUs) delivering tens of trillions of operations per second (TOPS) under strict mobile power and thermal limits. These accelerators efficiently handle latency-sensitive tasks such as image enhancement, speech recognition, and predictive features directly on-device.
However, advanced AI workloads — including large language models (LLMs), multi-modal reasoning, and high-fidelity generative models — demand substantially greater memory capacity, sustained compute throughput, and access to dynamic data than mobile hardware can provide within its power envelope. A typical flagship phone offers 8–16 GB of shared system memory and operates under a sustained power budget below 10 W. At the same time, cloud AI infrastructure relies on accelerators like the NVIDIA H100, which provide hundreds of gigabytes of high-bandwidth memory and orders-of-magnitude higher sustained throughput at data-center power levels.
Quick Answer
AI phones rely on cloud computing because smartphone mobile hardware operates under power, thermal, and memory constraints that limit its ability to sustain large-model AI workloads. the computational, memory, and data requirements of state-of-the-art AI, such as LLMs. Llama 3 70B needs ~140GB FP16 or ~35GB at 4-bit, which exceeds phone RAM.
Core Concept
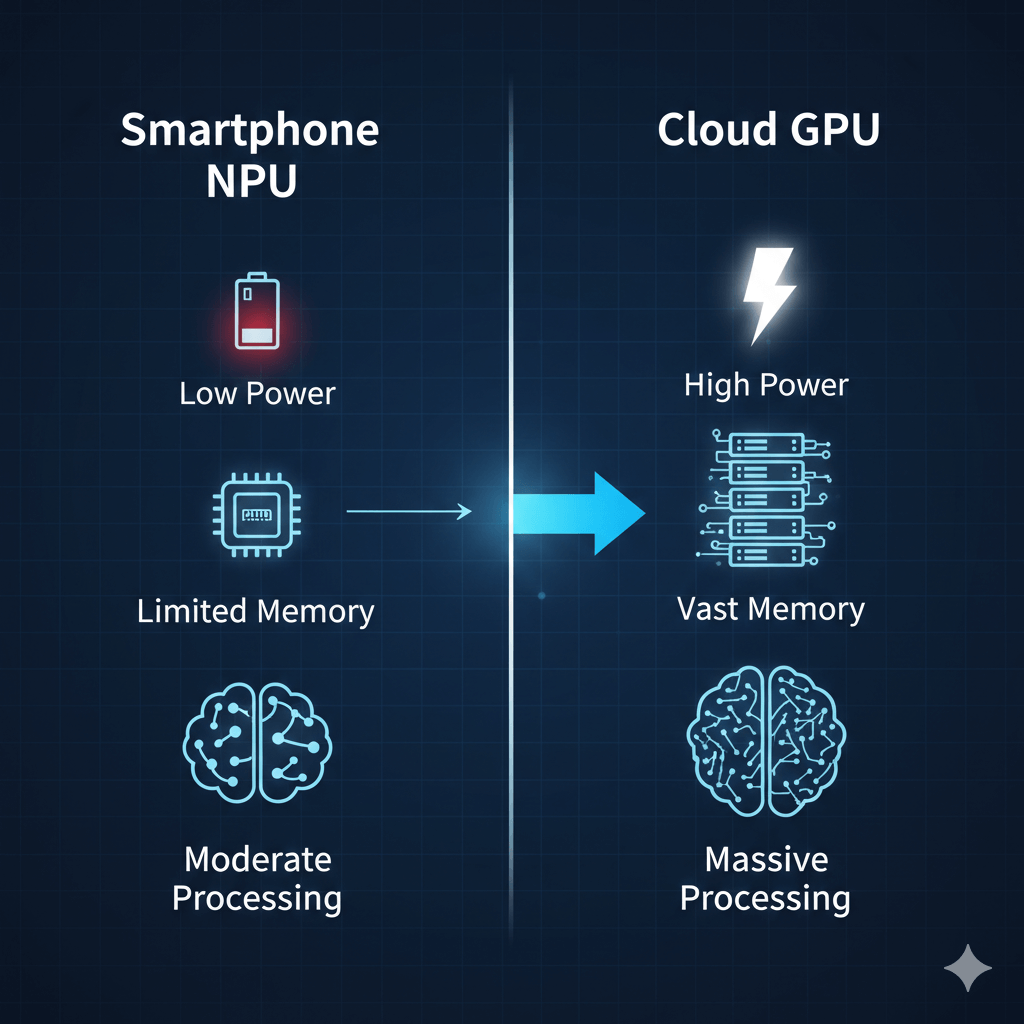
Hardware Capability Comparison
| Capability | Smartphone NPU | Laptop GPU | Datacenter GPU |
|---|---|---|---|
| Peak AI Throughput | Tens of TOPS (INT8 class) | Hundreds of TOPS (FP16/INT8 class) | Thousands of TOPS (tensor workloads) |
| Sustained Power | ~1–5 W (AI block) | 50–200W | 300–700+ W |
| Memory Available to Models | Shared system memory (8–16 GB typical) | 8–24 GB dedicated VRAM | 40–192 GB+ high-bandwidth memory |
| Cooling | Passive/thin vapor chamber | Active fan cooling | Liquid/industrial cooling |
| Practical Model Scale | Small, heavily optimized models | Mid-scale local models | Large language models & generative systems |
| Thermal Throttling | Common under sustained load | Occasional | Designed for sustained operation |
| Primary Use Case | Real-time, low-latency inference | Local AI development, gaming | Training, large-scale inference, generative AI |
On-device AI runs on specialized accelerators integrated into modern mobile SoCs, such as the Neural Engine in Apple chips, Hexagon DSPs in Qualcomm platforms, and AI accelerators in Google Tensor processors. These units are optimized for low-latency, energy-efficient inference and typically operate in the range of tens of TOPS for integer workloads. They excel at tasks where responsiveness and privacy are critical, including wake-word detection, image enhancement, face unlock, and predictive input.
However, mobile AI accelerators operate within strict limits in power delivery, cooling capacity, and memory bandwidth. Models deployed locally must therefore be heavily optimized, quantized, and constrained in size. While experimental deployments of multi-billion parameter models are possible, sustained real-time use is often limited by thermals, memory pressure, and battery consumption.
Cloud AI infrastructure, by contrast, aggregates large pools of compute accelerators, high-bandwidth memory, and distributed storage. Systems built around accelerators such as the NVIDIA A100 and NVIDIA H100 operate at data-center power levels and are designed for sustained high-throughput AI workloads. This environment enables deployment of significantly larger models, multi-modal systems, and workloads requiring extensive intermediate memory and parallelism.
The hybrid model emerges naturally from these constraints: edge devices handle latency-sensitive inference, while cloud systems handle scale-intensive computation.
How It Works
The operational model behind AI phone cloud dependency is based on dynamic task orchestration within a hybrid AI architecture. When a user initiates an AI-driven action, the device software determines whether the request can be handled locally or requires cloud-level processing power.
Tasks that demand instant response and strong privacy protection are handled on-device using specialized hardware such as Neural Processing Units found in platforms from Apple, Qualcomm, and Google. These processors power features like wake-word detection, camera enhancements, and sensor-driven inference. Similar principles are explained in how AI scene detection in phone cameras works and how AI-powered noise cancellation operates in earbuds, where ultra-low latency is essential.
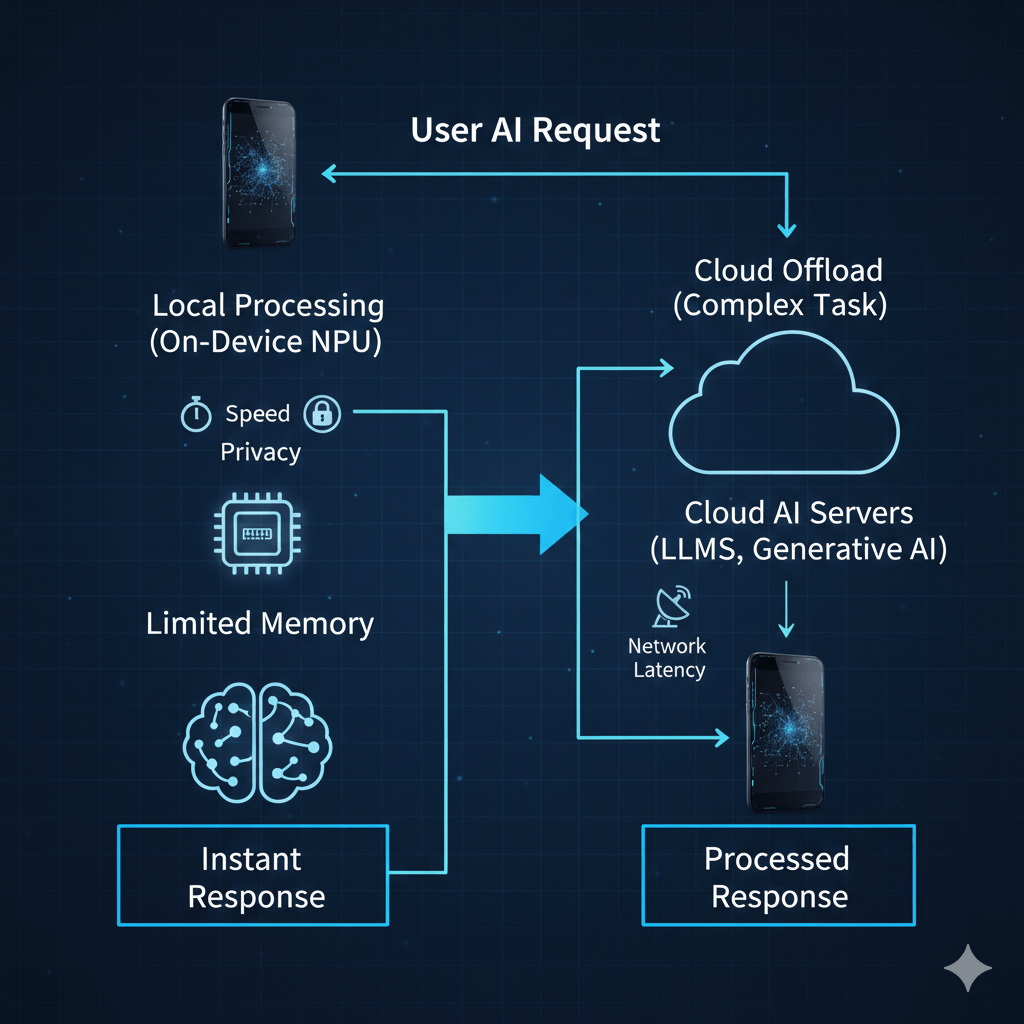
When a request exceeds local limits — such as multi-step reasoning, complex content generation, or large-model inference — the system securely offloads data to cloud infrastructure. The phone sends compressed input (voice, text, or image data) to remote inference services running on data-center accelerators such as the NVIDIA H100. These systems host large language models and generative AI models that require far more memory bandwidth and sustained throughput than mobile hardware can support.
This round-trip process introduces network latency, which can range from tens to hundreds of milliseconds for connectivity alone, with additional time required for server-side model inference. That trade-off between speed and capability is a central theme in on-device AI vs cloud AI design decisions across modern consumer devices.
Once processing is complete, the generated result — whether text, image data, or structured output — is returned to the phone, where local processors handle rendering and final interaction. This workflow creates an “intelligent fallback” system: edge hardware handles real-time inference, while cloud systems handle scale-intensive computation. The same architectural pattern is now extending beyond phones into AI wearables and other local AI gadgets, where edge devices increasingly act as front-end nodes for larger AI systems.
Key Capabilities
Cloud infrastructure unlocks capabilities for smartphones that extend well beyond what can be sustained within mobile power, thermal, and memory limits. This is where the distinction between on-device AI limitations and cloud AI benefits becomes most visible.
Scale and Model Complexity
Cloud platforms host models with tens to hundreds of billions of parameters — and potentially larger undisclosed systems — far exceeding what mobile devices can store or execute efficiently. Open-weight models released by Meta AI illustrate how memory requirements alone quickly reach tens of gigabytes even under aggressive quantization. This scale enables deeper contextual understanding and multi-step reasoning that smaller on-device models cannot consistently sustain.
Sustained Computational Throughput
Data centers aggregate accelerators such as the NVIDIA H100, designed for continuous high-throughput AI workloads. Unlike smartphones, which must manage heat and battery drain, these systems operate at data-center power levels with industrial cooling. This allows complex operations like video understanding, large-scale summarization, and high-resolution generative AI to run without the thermal throttling that affects mobile processors. The performance differences here reflect broader AI processing on smartphones’ constraints related to memory bandwidth and sustained compute.
Dynamic Knowledge Integration
Cloud-based AI systems can integrate real-time data sources, search systems, and continuously updated knowledge repositories. On-device models typically operate with static knowledge between software updates. This difference explains why cloud-backed assistants can answer current-event questions, while offline systems are limited to preloaded information — a contrast also central to on-device AI vs cloud AI architecture decisions.
Resource-Intensive Generative AI
Tasks such as photorealistic image synthesis, complex video editing, and multi-modal content generation involve substantial intermediate tensors and memory usage. Even optimized mobile pipelines often rely on cloud backends for final rendering stages. Similar hybrid behavior can be seen in camera processing workflows discussed in AI scene detection in phone cameras, where segmentation may occur locally while advanced generative operations are offloaded.
Rapid Model Updates and Training
Training foundation models requires distributed infrastructure operating across thousands of accelerators — a scale not feasible on consumer hardware. Cloud deployment also allows continuous model updates without requiring users to download large new model packages. This evolving model lifecycle increasingly extends to AI wearables and local AI gadgets, which act as edge endpoints connected to cloud intelligence.
Real-World Usage
Despite the advantages of hybrid AI systems, users frequently encounter limitations that stem directly from the division between on-device processing and cloud dependency.
Connectivity Dependence
Advanced AI features often require a stable internet connection. In areas with weak coverage or high network congestion, features such as complex voice queries, generative editing, or large-model inference may fail or become unavailable. This limitation reflects a core trade-off in AI phone cloud dependency: access to large-scale intelligence comes at the cost of network reliance.
Latency and Response Delays
When requests are offloaded, total response time includes network round-trip delay plus server-side processing. While local inference can feel instantaneous, cloud-backed operations may take noticeably longer, particularly for generative tasks. This difference highlights why real-time features remain on-device while scale-intensive workloads run remotely.
Privacy and Data Transmission Concerns
Cloud processing requires sending voice, image, or text data to remote servers. Although encryption and anonymization are standard practices, the act of transmitting personal data introduces privacy considerations that do not exist with fully local inference.
Increased Data Usage
AI tasks involving media — such as image editing or voice interaction — require transferring data between device and server. Frequent use of cloud-assisted features can noticeably increase mobile data consumption compared to purely local processing.
Service Reliability
Cloud AI systems depend on remote infrastructure availability. Outages or service disruptions can temporarily disable AI-powered features, even when the device itself is functioning normally.
System-Level Explanation
Performance drops, device heating, and battery drain are often attributed to individual applications, but they are more accurately explained by system-level resource management. Modern smartphones operate within tightly constrained thermal and power envelopes, and AI workloads stress the same shared resources used by the CPU, GPU, memory subsystem, and modem.
Thermal Throttling
Mobile devices rely on passive cooling systems with limited heat dissipation capacity. When sustained computational load from AI inference, graphics, or combined workloads exceeds thermal limits, the operating system reduces processor clock speeds to prevent overheating. This process — thermal throttling — directly lowers performance to maintain hardware safety and device longevity.
Memory Pressure
Smartphones use shared system memory across all processing units. As AI tasks increase memory utilization, the operating system may terminate background processes, compress memory, or increase swap activity. These behaviors can introduce lag, app reloads, and inconsistent responsiveness, particularly during heavy multitasking or prolonged AI use.
Dynamic Power Management
Mobile platforms continuously adjust voltage and frequency based on battery level, temperature, and workload. Under sustained load or low battery conditions, AI accelerators and graphics processors may operate below peak performance levels. This dynamic scaling preserves battery life and prevents thermal runaway, but reduces sustained throughput compared to brief peak benchmarks.
Sustained vs Peak Performance
AI accelerators in smartphones are often advertised using peak throughput metrics, but sustained real-world performance is constrained by thermals and power delivery. Extended AI tasks, therefore, exhibit reduced token generation rates, slower inference, or decreased frame processing speeds over time.
These behaviors are not defects but expected outcomes of operating high-compute workloads inside a handheld device. They illustrate why large-scale inference and generative AI remain better suited to cloud environments designed for continuous high-power operation.
Industry Direction
The industry is not moving toward eliminating the cloud — it is refining the balance between local intelligence and remote scale. Advances in silicon design, model efficiency, and distributed architectures are expanding on-device capabilities while preserving the cloud as the backbone for large-scale AI.
More Capable On-Device Hardware
Mobile chip designers are increasing AI throughput, memory bandwidth, and efficiency with each generation. Platforms from companies such as Qualcomm, Apple, and Google continue to improve local inference performance for vision, speech, and personalization tasks. These advances allow mid-scale models and more complex pipelines to run at the edge, reducing unnecessary cloud round-trips.
Smaller, More Efficient Models
Research in quantization, pruning, and distillation is producing models that deliver stronger performance per watt. While these optimizations do not eliminate the need for cloud-scale models, they expand what can be handled locally under mobile power limits. This evolution is central to the broader shift toward more capable local AI gadgets and distributed edge systems.
Edge Nodes and Distributed AI
Beyond individual devices, computing is increasingly distributed across regional edge servers and network nodes. These systems reduce latency and improve privacy by processing data closer to users while still relying on centralized infrastructure for large-model execution.
Privacy-Preserving Learning
Techniques such as federated learning enable models to improve using decentralized data without transmitting raw user information. This approach allows personalization while addressing some privacy concerns associated with cloud processing.
Smarter Hybrid Orchestration
AI frameworks are becoming more adaptive in deciding where tasks should run. Factors such as network conditions, battery state, and thermal headroom increasingly influence whether inference remains local or is offloaded. This dynamic allocation model is now extending into AI wearables, which operate as lightweight edge nodes connected to broader AI ecosystems.
Despite these advances, fundamental economic and engineering constraints remain. Data-center accelerators like the NVIDIA H100 operate at power levels and memory capacities that cannot be replicated in handheld devices. As a result, the future of AI is not “edge versus cloud,” but a deeper integration of both.
Technical Context
Modern AI workloads are constrained more by memory bandwidth, thermal envelopes, and sustained compute capacity than by peak theoretical throughput metrics alone. Mobile system-on-chip (SoC) platforms operate within strict power budgets — typically under 10 W sustained — which limits how long high-throughput AI inference can run compared to data-center accelerators designed for continuous high-power operation.
These constraints are architectural characteristics of mobile hardware, not temporary software inefficiencies. They explain why hybrid on-device and cloud AI designs have become the prevailing model across consumer systems.
Key Takeaways
- Hybrid AI is the standard model.
- Modern AI phones combine on-device inference for speed and privacy with cloud infrastructure for scale, model complexity, and dynamic data access.
- Cloud systems provide scale and sustained performance.
- Data-center infrastructure enables large language models, advanced generative AI, and multi-modal processing that exceed mobile power, memory, and cooling limits.
- On-device AI prioritizes efficiency and responsiveness.
- Local processing supports real-time tasks such as vision enhancement, sensor fusion, and speech detection, where low latency and privacy are critical.
- Mobile hardware constraints are architectural, not temporary.
- Power delivery, thermal dissipation, and shared memory bandwidth limit how long high-throughput AI workloads can run on handheld devices.
- Trade-offs are inherent to cloud-assisted AI.
- Offloading enables advanced capabilities but introduces latency, connectivity dependence, and data transmission considerations.
- The future is deeper integration, not replacement.
- Advances in edge hardware and efficient models will expand local capabilities, but cloud infrastructure will remain essential for large-scale training and complex inference.
Evidence & Methodology
This analysis is based on:
- Public research on AI model scaling and inference architectures
- Documented capability ranges for mobile NPUs and system-on-chip (SoC) power envelopes
- Published specifications for cloud accelerators and large-scale model deployment practices
- Hybrid edge/cloud AI system design patterns used in commercial platforms
- Engineering principles related to memory bandwidth, thermal throttling, and sustained compute limits
Performance figures reflect industry-reported ranges and architectural norms rather than device-specific benchmarks.
Frequently Asked Questions
Can AI phones perform any AI tasks offline?
Yes. Many foundational AI features operate entirely on-device, including face unlock, image enhancement, wake-word detection, and predictive text. These tasks rely on compact models optimized for mobile hardware and are designed for low latency and privacy.
Is on-device AI getting powerful enough to replace cloud AI entirely?
On-device AI capabilities are improving with more efficient hardware and models, but cloud systems remain essential for large-scale reasoning, multi-modal processing, and high-fidelity generative AI. The difference stems from power, cooling, and memory constraints rather than software limitations.
What are the main privacy implications of AI phone cloud dependency?
Cloud processing involves transmitting user data such as voice, images, or text to remote servers. While encryption and security practices are standard, the reliance on remote infrastructure introduces considerations that do not exist with fully local inference.
Does using AI features increase mobile data usage?
Yes. Tasks that send media or large prompts to cloud services can increase data usage compared to purely local processing. Frequency and task type determine the impact.
Does using cloud-dependent AI features consume a lot of mobile data?
Yes. Cloud-assisted AI features transfer data between devices and servers, especially for media-heavy tasks such as image editing or voice interaction. Usage depends on task frequency and content size.