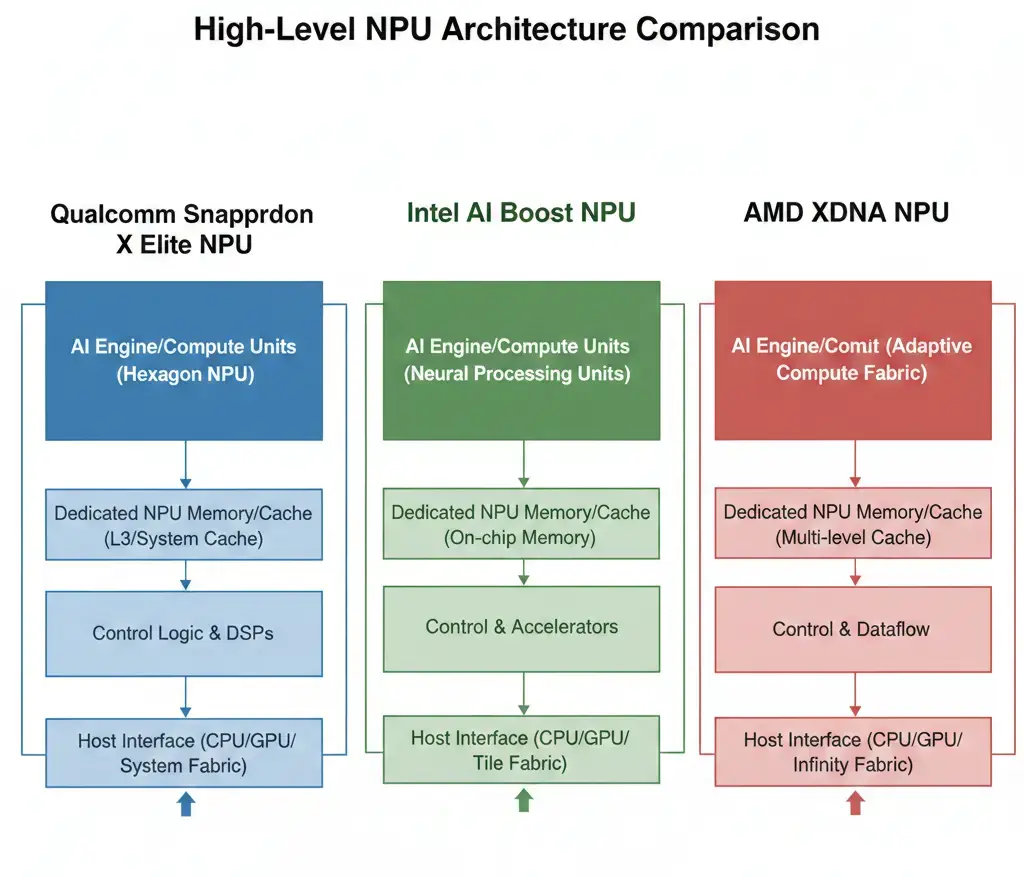
The choice between Snapdragon X Elite vs Intel AI Boost vs AMD XDNA reveals distinct architectural philosophies for on-device AI acceleration. Qualcomm’s Snapdragon X Elite emphasizes sustained performance and power efficiency within mobile power envelopes via its integrated Hexagon NPU. Intel AI Boost, part of the Core Ultra series, leverages a modular tile-based design with a dedicated NPU, scaling performance in upcoming generations. AMD XDNA, found in Ryzen AI processors, offers a dedicated NPU block with evolving capabilities, including block sparsity in its next iteration, aiming for a balance of performance and efficiency. Each design targets efficient execution of neural network inference workloads.
Neural Processing Units (NPUs) are specialized co-processors engineered to accelerate artificial intelligence (AI) workloads, particularly neural network inference. Unlike general-purpose CPUs or graphics-focused GPUs, NPUs feature highly parallel architectures with dedicated Multiply-Accumulate (MAC) units, optimized for low-precision arithmetic (e.g., INT8, INT4). This specialization allows them to execute repetitive, data-intensive AI operations with higher power efficiency and lower latency within defined thermal and power envelopes.
Integrating NPUs into System-on-Chips (SoCs) for consumer devices, robotics, and industrial hardware is critical. It enables always-on AI features, enhances privacy by keeping data on-device, and extends battery life by offloading AI tasks from more power-hungry components. Understanding the underlying silicon architecture, memory hierarchy, and interconnects of these NPUs is crucial for engineers designing next-generation AI-powered systems.
Qualcomm Snapdragon X Elite (Hexagon NPU)
The Snapdragon X Elite integrates Qualcomm’s Hexagon NPU, an architecture designed for sustained AI inference within mobile power envelopes. This NPU is part of a broader heterogeneous compute platform that includes the Adreno GPU and Kryo CPU cores. Its architecture focuses on performance per watt, crucial for thin-and-light devices, aligning with the growing trend of NPU integration in smartphones. The Hexagon NPU handles a wide range of AI models, from computer vision to natural language processing, by efficiently executing tensor operations.
Intel AI Boost (NPU Tile)
Intel AI Boost is a dedicated NPU tile within Intel’s Core Ultra processors, starting with Meteor Lake. This NPU is distinct from the integrated Arc Graphics GPU and CPU cores, operating as a specialized accelerator for AI tasks. Its tile-based architecture, enabled by Intel’s Foveros packaging technology, allows for flexible integration and process node mixing. The NPU is designed to offload AI workloads, improving system responsiveness and power efficiency for tasks like background blur, eye contact correction, and local LLM inference, subject to interconnect bandwidth.
AMD XDNA (Ryzen AI Engine)
AMD XDNA, branded as Ryzen AI, is a dedicated AI engine integrated into AMD’s Ryzen processors, beginning with the 7040 series. This NPU block operates alongside the Zen CPU cores and RDNA graphics. Its purpose is to provide efficient acceleration for AI inference, particularly for consumer-facing features and productivity applications. The upcoming XDNA 2 architecture introduces block sparsity, a technique that further enhances efficiency by skipping computations on zero-valued data, reducing power consumption and latency for optimized models. When evaluating Snapdragon X Elite vs Intel AI Boost vs AMD XDNA, efficiency ultimately depends on workload characteristics and power constraints. The Snapdragon X Elite vs Intel AI Boost vs AMD XDNA performance comparison shows rapid scaling of NPU TOPS across generations.
Snapdragon X Elite vs Intel AI Boost vs AMD XDNA: Architectural Differences
The core distinction among these NPUs, central to any Snapdragon X Elite vs Intel AI Boost vs AMD XDNA, lies in their silicon-level integration, process technology, and specific architectural optimizations.

While all aim for efficient AI inference, their approaches to achieving this vary, impacting performance, power, and memory interaction.
| Feature | Snapdragon X Elite (Hexagon NPU) | Intel AI Boost (NPU Tile) | AMD XDNA (Ryzen AI Engine) |
|---|---|---|---|
| NPU Architecture | Qualcomm Hexagon | Dedicated NPU Tile (Meteor Lake, Lunar Lake) | AMD XDNA (Ryzen AI), XDNA 2 (Strix Point) |
| Process Node | TSMC N4 | Intel 4 (Meteor Lake compute), Intel 18A (Lunar Lake) | TSMC N4 (Ryzen 7040/8040), TSMC N4/N3 (Strix Point) |
| Peak NPU TOPS (Current) | Up to 45 TOPS | Up to 11 TOPS (Meteor Lake), 48 TOPS (Lunar Lake) | Up to 16 TOPS (Ryzen 8040), 50 TOPS (Strix Point) |
| Memory Integration | Integrated LPDDR5X controller | Integrated LPDDR5/5X controller, on-package LPDDR5X (Lunar Lake) | Integrated LPDDR5/5X controller |
Qualcomm’s Hexagon NPU is deeply embedded within its SoC, leveraging a mature mobile-first design philosophy. Intel’s modular approach with Foveros allows for rapid iteration and integration of specialized tiles, as detailed in the Intel AI Boost documentation. AMD’s XDNA focuses on a dedicated block, with XDNA 2 introducing advanced sparsity techniques for efficiency gains.
Performance Comparison
When evaluating NPU performance, peak TOPS (Trillions of Operations Per Second) serve as a headline metric, but sustained performance under real-world workloads is more indicative. The Snapdragon X Elite, with up to 45 TOPS, aims for sustained performance within mobile power envelopes, subject to thermal limits. This allows for longer-duration AI tasks without significant throttling.

Intel’s AI Boost in Meteor Lake offers up to 11 NPU TOPS, with a total system performance (CPU+GPU+NPU) of 34 TOPS. The upcoming Lunar Lake boosts this to 48 NPU TOPS and 120 total TOPS, indicating a rapid scaling of AI capabilities. AMD’s Ryzen 8040 series provides up to 16 NPU TOPS, with the future Strix Point (XDNA 2) targeting 50 NPU TOPS. These figures represent the theoretical maximum throughput for specific low-precision operations. Actual performance depends on the AI model’s architecture, data types, software stack efficiency, and memory bandwidth ceilings, especially for tasks like AI image processing where ISPs and NPUs often work in tandem.
Power & Thermal Behavior
Power efficiency is a critical design goal for all three NPUs, especially for embedded and consumer devices where battery life and thermal management are paramount. NPUs are inherently more power-efficient for AI inference than CPUs or GPUs because they are purpose-built for these specific operations.
The Snapdragon X Elite’s Hexagon NPU is designed from the ground up for mobile power envelopes, aiming for performance within strict thermal limits. This allows for sustained AI workloads in fanless or passively cooled designs. Intel’s AI Boost, particularly with Lunar Lake’s on-package memory, is expected to further reduce power consumption by minimizing the energy required for data movement. AMD’s XDNA, especially with XDNA 2’s block sparsity, directly addresses power efficiency by reducing unnecessary computations for optimized models. Efficient power management translates directly into longer battery life for laptops and more compact, passively cooled designs for edge AI devices.
Memory & Bandwidth Handling
Efficient memory access and high bandwidth are crucial for NPU performance, as AI models often require large amounts of data to be moved between system memory and the NPU. All three architectures leverage integrated LPDDR5/5X memory controllers, providing high-bandwidth, low-latency access to system RAM, with differences in memory hierarchy.
The Snapdragon X Elite’s tightly integrated design ensures optimized data paths between the Hexagon NPU and the LPDDR5X memory, minimizing interconnect limitations. Intel’s Lunar Lake takes this a step further by integrating LPDDR5X memory directly on-package. This reduces latency and power consumption associated with external memory traces, providing the NPU with a dedicated, high-speed memory channel. AMD’s XDNA also benefits from its integrated memory controller, ensuring that the NPU can feed its compute units efficiently. The ability to quickly load model weights and input data, and store intermediate results, directly impacts the NPU’s overall throughput and responsiveness.
Real-World Deployment
The practical implications of these NPU architectures are evident across various deployment scenarios. In consumer devices like laptops, these NPUs enable features such as real-time video effects (background blur, noise suppression), local LLM inference for enhanced productivity, and always-on voice assistants, all while preserving battery life within specified power envelopes.
For industrial hardware and robotics, NPUs facilitate on-device computer vision for quality control, predictive maintenance, and autonomous navigation, reducing reliance on cloud connectivity and improving real-time decision-making, a key advantage in the on-device AI vs cloud AI debate. In healthcare devices, they can power real-time anomaly detection from sensor data or accelerate medical image analysis at the edge. The choice of NPU impacts the system’s ability to handle specific AI workloads, its power budget, and the overall cost-performance ratio for the target application. Developers leverage frameworks like NNAPI (Android) or ONNX Runtime with vendor-specific execution providers to abstract hardware differences, but optimal performance often requires vendor-specific tools and SDKs.
Which Design Is More Efficient
Determining which design is “more efficient” depends heavily on the specific workload, power budget, and performance requirements, reflecting architectural trade-offs. For scenarios demanding sustained AI performance within strict power envelopes, such as thin-and-light laptops or passively cooled edge devices, the Snapdragon X Elite’s Hexagon NPU, with its mobile-first design, presents a strong case. Its architecture is optimized for continuous, power-efficient operation.
Intel’s AI Boost, with the performance leap in Lunar Lake and its on-package memory, offers compelling efficiency for bursty and sustained AI workloads, especially where system-level integration benefits from the modular tile approach and reduced data movement. This design can be highly efficient for tasks requiring rapid AI acceleration. AMD’s XDNA, especially with the upcoming XDNA 2’s block sparsity, is poised to deliver excellent efficiency by intelligently reducing redundant computations for optimized models. This is particularly beneficial for sparse models common in many AI applications. Ultimately, the most efficient NPU is the one that best matches the specific computational demands and power constraints of the target application, supported by a robust and optimized software stack.
Key Takeaways
- Specialized Acceleration: NPUs from Qualcomm, Intel, and AMD are purpose-built for AI inference, offering superior power efficiency and lower latency compared to CPUs or GPUs for these tasks, within power envelopes.
- Architectural Diversity: Each vendor employs distinct architectural approaches, from Qualcomm’s tightly integrated Hexagon NPU to Intel’s modular tile-based AI Boost and AMD’s dedicated XDNA engine with upcoming sparsity optimizations, reflecting architectural trade-offs and interconnects.
- Performance Scaling: NPU performance, measured in TOPS, is rapidly increasing across all platforms, with upcoming generations (Intel Lunar Lake, AMD Strix Point) showing significant gains in peak and sustained throughput.
- Power & Memory Integration: Power efficiency and optimized memory access (LPDDR5X, on-package memory) are critical for sustained performance and battery life in embedded and consumer devices, directly impacting data movement and latency.
- Workload-Dependent Efficiency: The “most efficient” NPU is subjective, depending on the specific AI workload, thermal budget, and the overall software-hardware optimization for a given application.