Summary
AI Smart Home Hubs use local AI processing to enable faster automation, improved privacy, and reliable smart home control without relying on cloud servers.
Table of Contents
AI Smart Home Hubs are evolving to incorporate significant local intelligence, shifting core AI inference from the cloud to the device. This architectural change directly addresses performance bottlenecks associated with network latency and cloud resource contention, enabling deterministic, low-latency execution for critical functions. By leveraging specialized on-device compute units and sophisticated runtime scheduling, these hubs deliver enhanced privacy, reliability, and responsiveness, even during internet outages.
The escalating demand for highly responsive, private, and reliable smart home experiences has exposed significant performance bottlenecks inherent in traditional cloud-centric AI models. Relying on remote servers for critical inference introduces unpredictable latency, network dependencies, and privacy concerns that degrade user experience and system reliability. This engineering challenge has driven a fundamental architectural shift towards local intelligence in AI Smart Home Hubs, where optimized runtime scheduling and on-device processing are paramount to overcoming these limitations and delivering consistent, low-latency AI inference at the edge.
This shift toward on-device intelligence is closely related to the broader concept of edge AI, where machine learning inference happens directly on local devices rather than centralized cloud servers.
What Are AI Smart Home Hubs?
AI Smart Home Hubs with local intelligence are central control units designed to process and execute artificial intelligence tasks directly on the device, rather than offloading them entirely to cloud servers. This paradigm shift means that functions like voice command recognition, presence detection, security monitoring, and complex automation rules are handled by the hub’s integrated hardware. The core objective is to minimize reliance on external network connectivity and cloud compute, ensuring faster response times, enhanced data privacy, and continuous operation.
How Local AI Works in Smart Home Hubs
At its core, a locally intelligent AI Smart Home Hub operates by capturing sensor data (e.g., audio, video, motion, environmental readings) and feeding it into on-device AI models. An embedded operating system, coupled with a specialized AI runtime, orchestrates the processing of this data across a heterogeneous compute architecture Local AI Gadgets. For instance, a Digital Signal Processor (DSP) might handle low-power “wake word” detection, while a Neural Processing Unit (NPU) takes over for more complex natural language understanding or object recognition, using optimized models.
The system’s runtime scheduler is critical here. It prioritizes tasks based on urgency and resource availability, ensuring that time-critical events—like a security alert or an immediate voice command—are given precedence and executed with minimal latency. This direct control over the execution queue and resource allocation allows for highly deterministic responses, a stark contrast to the variable delays experienced with cloud-dependent systems. Post-inference, the hub triggers local actions (e.g., turning on lights, locking doors) or sends only anonymized, actionable metadata to the cloud, preserving raw data privacy.
Architecture of AI Smart Home Hubs
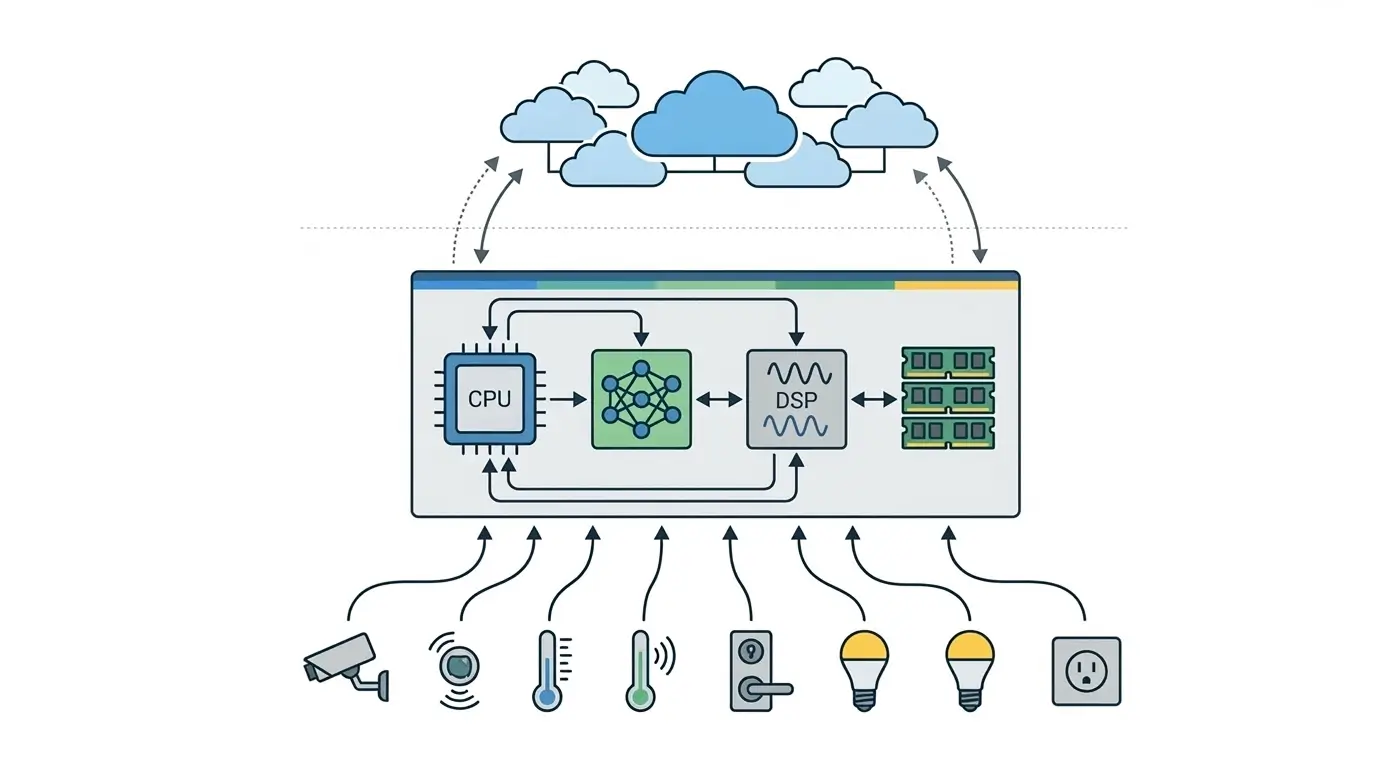
The architecture of a modern AI Smart Home Hub is built around a System-on-Chip (SoC) that integrates multiple specialized processing units. This heterogeneous design allows the device to efficiently perform local AI inference without relying entirely on cloud infrastructure.
Architecture diagram of an AI Smart Home Hub showing heterogeneous processors such as CPU, NPU, and DSP used for local AI inference.
These hubs typically combine several processors optimized for different workloads:
- CPU (Central Processing Unit) – Handles general system operations, automation logic, and the operating system.
- NPU (Neural Processing Unit) – Accelerates AI inference tasks such as object recognition, voice command processing, and pattern detection. A Neural Processing Unit is a specialized processor designed specifically to accelerate machine learning workloads on edge devices.
- DSP (Digital Signal Processor) – Processes real-time sensor data such as audio streams for wake-word detection or sound analysis.
- System Memory – Stores AI model weights, intermediate activations, and runtime data required for on-device processing.
An embedded operating system and AI runtime coordinate how workloads are distributed across these processors.

The runtime is responsible for managing several critical system functions:
Task Scheduling
AI inference tasks are assigned to the most suitable processor—CPU, NPU, or DSP—based on the model type, computational complexity, and real-time requirements.
Memory Management
The runtime allocates and manages memory used for model parameters, intermediate activations, and input/output data across multiple memory hierarchies such as cache, DRAM, and accelerator memory.
Data Movement
Efficient data transfer between processors and memory is coordinated through the Network-on-Chip (NoC) to minimize latency and maximize throughput.
Power Management
Clock frequencies and processor states are dynamically adjusted to balance performance with thermal limits and energy efficiency.
These runtime optimizations ensure that AI Smart Home Hubs maintain consistent performance, low latency, and reliable operation, even when handling multiple concurrent AI tasks.
Performance Benefits of Local AI
The shift to local AI in Smart Home Hubs fundamentally alters performance characteristics, primarily driven by runtime scheduling decisions.
- Execution Determinism: Local processing significantly reduces the unpredictable latency and variability introduced by WAN round-trips and shared cloud server loads. The embedded OS and AI runtime have direct control over task execution, leading to highly predictable and consistent response times. This is critical for security systems and immediate voice command processing.
- Low Latency: By removing network overhead, local inference significantly reduces end-to-end latency. A “wake word” can be detected and acted upon in milliseconds, as opposed to hundreds of milliseconds or seconds with cloud processing. The runtime prioritizes these low-latency tasks on dedicated, high-efficiency hardware, depending on workload and available resources.
- Enhanced Privacy: Sensitive raw data (e.g., voice recordings, video streams) is designed to remain on the device, a principle shared with other AI Smart Rings Explained and local AI gadgets. Inference occurs locally, and only anonymized commands or metadata are potentially transmitted. This is a direct architectural constraint enforced by the local runtime, which schedules compute cycles to transform sensitive input into privacy-preserving output.
- Operational Autonomy: Core functionalities remain operational even during internet outages. The runtime ensures that essential automations and security features continue to function, as their scheduling is entirely self-contained.
However, these benefits come with complex performance tradeoffs, particularly in runtime optimization:
- Runtime Complexity of Heterogeneous Compute: Efficiently orchestrating tasks across a mosaic of specialized units (CPU, NPU, DSP) is a significant challenge.
- Data Movement Overhead: Moving intermediate activations and model weights between different memory domains (CPU caches, DRAM, NPU scratchpads) via the Network-on-Chip (NoC) incurs latency and power. An inefficient runtime scheduler can spend more time moving data than performing actual inference, especially for small, bursty tasks.
- Context Switching Penalties: Switching the NPU between different AI models (e.g., from wake-word detection to a complex command recognition model) requires loading new weights and configurations, which can introduce delays. The runtime must intelligently minimize these switches or pre-load frequently used models, impacting the memory footprint.
- Model Quantization: To fit models into limited memory and achieve real-time inference on constrained NPUs, aggressive quantization (e.g., INT8, INT4) is often mandatory. This is a direct runtime optimization that trades off model accuracy for speed and memory footprint, requiring careful validation to ensure an acceptable user experience for the target application.
- Scheduling Under Thermal Constraints: Smart home hubs are typically passively cooled. Sustained high-performance operation of NPUs or CPUs generates heat. The runtime scheduler must actively monitor thermal sensors and dynamically throttle clock frequencies or even temporarily disable cores to prevent overheating. This means advertised peak performance (e.g., TOPS) is rarely sustained for continuous workloads, leading to increased inference latency or dropped events. The scheduler must prioritize critical tasks during throttling.
- Resource Contention for Shared Memory: While NPUs have dedicated scratchpads, large models and intermediate data often reside in main DRAM. Multiple concurrent AI tasks (e.g., wake-word, facial recognition, sound event detection) will contend for DRAM bandwidth. The memory controller, managed by the OS, can become a bottleneck, leading to increased latency as processing units wait for data.
Real-World Applications of AI Smart Home Hubs
The predictable and low-latency performance enabled by local AI and sophisticated runtime scheduling is critical for several smart home applications:
- Security Systems: Real-time glass break detection, smoke alarm recognition, and immediate facial recognition for access control or intruder alerts. The deterministic runtime ensures these critical events are processed and acted upon without network-induced delays.
- Voice Assistants: Instantaneous “wake word” detection and local command recognition. This provides a fluid, responsive user experience, as the hub doesn’t need to wait for cloud processing for basic commands.
- Local Automation: Motion-triggered lighting, door lock/unlock based on presence, and environmental controls that operate reliably even without an internet connection. The embedded OS schedules these tasks autonomously.
- Privacy-Sensitive Monitoring: Continuous audio analysis for specific sound events (e.g., baby crying, dog barking) or video analytics for package delivery detection, where raw data is processed on-device.
Limitations of Local AI Smart Home Devices
Despite its advantages, the local AI paradigm for Smart Home Hubs presents several limitations:
- On-Device Resource Constraints: Local hubs operate within strict power, memory, and compute budgets. This limits the size and complexity of AI models that can be deployed and the number of concurrent tasks that can run at peak performance.
- Runtime Optimization Complexity: Developing and maintaining an efficient runtime that intelligently schedules tasks across a heterogeneous SoC, manages data movement, and handles thermal/power constraints is a highly complex engineering challenge.
- Model Update and Management: Over-the-air (OTA) updates for large, complex AI models can be resource-intensive and require robust mechanisms to ensure integrity and compatibility with the local runtime. Such updates, especially for large models, can significantly impact battery life on portable hubs or temporarily degrade offline execution capabilities during the update process.
- Scalability for Novel AI: While effective for known tasks, local hubs may struggle with entirely new, computationally intensive AI models that require vast cloud-scale resources for training or inference, necessitating a hybrid approach.
Why AI Smart Home Hubs Matter
The architectural shift to local intelligence in AI Smart Home Hubs, driven by a focus on runtime scheduling and performance bottleneck analysis, is significant for the evolution of smart living. It fundamentally redefines the performance envelope of these devices, moving from best-effort cloud responsiveness to highly deterministic local execution. This enables new classes of applications that demand real-time, private, and reliable responses, such as advanced security and context-aware automation.
Furthermore, it shifts the primary engineering challenge from network optimization to sophisticated on-device resource management, driving innovation in SoC design, embedded AI runtimes, and efficient model deployment. Ultimately, this approach enhances the longevity and resilience of smart home functionality against internet outages and evolving privacy concerns, delivering a more robust and trustworthy user experience.
Key Takeaways
- AI Smart Home Hubs are transitioning to local intelligence to overcome cloud-centric performance bottlenecks like latency and non-determinism.
- This shift relies on heterogeneous SoC architectures (CPU, NPU, DSP) and sophisticated embedded OS/AI runtimes for efficient task scheduling.
- Key benefits include deterministic, low-latency execution, enhanced data privacy, and operational autonomy during internet outages.
- Engineering challenges include optimizing runtime for heterogeneous compute (data movement, context switching), managing thermal constraints, and mitigating shared-memory contention.
- Local AI enables critical real-world applications like real-time security, responsive voice assistants, and reliable local automations.
- Limitations include on-device resource constraints, the complexity of runtime optimization, and challenges in model updates.
FAQ: AI Smart Home Hubs
What is an AI Smart Home Hub?
An AI Smart Home Hub is a central smart home device that runs artificial intelligence locally to control automation, voice commands, and security systems without relying entirely on the cloud.
Why is local AI important for smart homes?
Local AI reduces latency, improves privacy, and allows smart home devices to function even when the internet is unavailable.
Do AI Smart Home Hubs work without an internet connection?
Yes. Many AI smart home hubs perform key functions locally, allowing automation, voice commands, and security monitoring to work offline.