Summary
This article compares fully local and hybrid cloud architectures used in AI smart speakers, focusing on performance, privacy, hardware requirements, and system design trade-offs.
Table of Contents
AI in Smart Speakers fundamentally relies on two primary compute architectures: fully local processing, where all Automatic Speech Recognition (ASR), Natural Language Understanding (NLU), and Text-to-Speech (TTS) tasks execute directly on-device, and a hybrid cloud-centric model, which offloads complex AI tasks to remote servers. The fully local paradigm prioritizes data sovereignty and deterministic latency but demands significantly higher on-device compute, memory, and power budgets, leading to increased Bill of Materials (BOM) and constrained AI model fidelity. Conversely, the hybrid approach enables broader AI capabilities and a lower device BOM by leveraging scalable cloud resources, albeit at the cost of network dependency and inherent data transmission.
The architectural design of AI in Smart Speakers presents a critical engineering challenge: balancing the computational demands of sophisticated AI models with the stringent resource constraints of embedded hardware. This decision dictates not only the device’s performance, privacy posture, and feature set but also its manufacturing cost and operational complexity. Understanding the silicon-level implications, runtime execution characteristics, and system bottlenecks of fully local versus hybrid cloud-centric architectures is paramount for architects designing the next generation of intelligent edge devices.
How AI in Smart Speakers Uses Local and Cloud Architectures
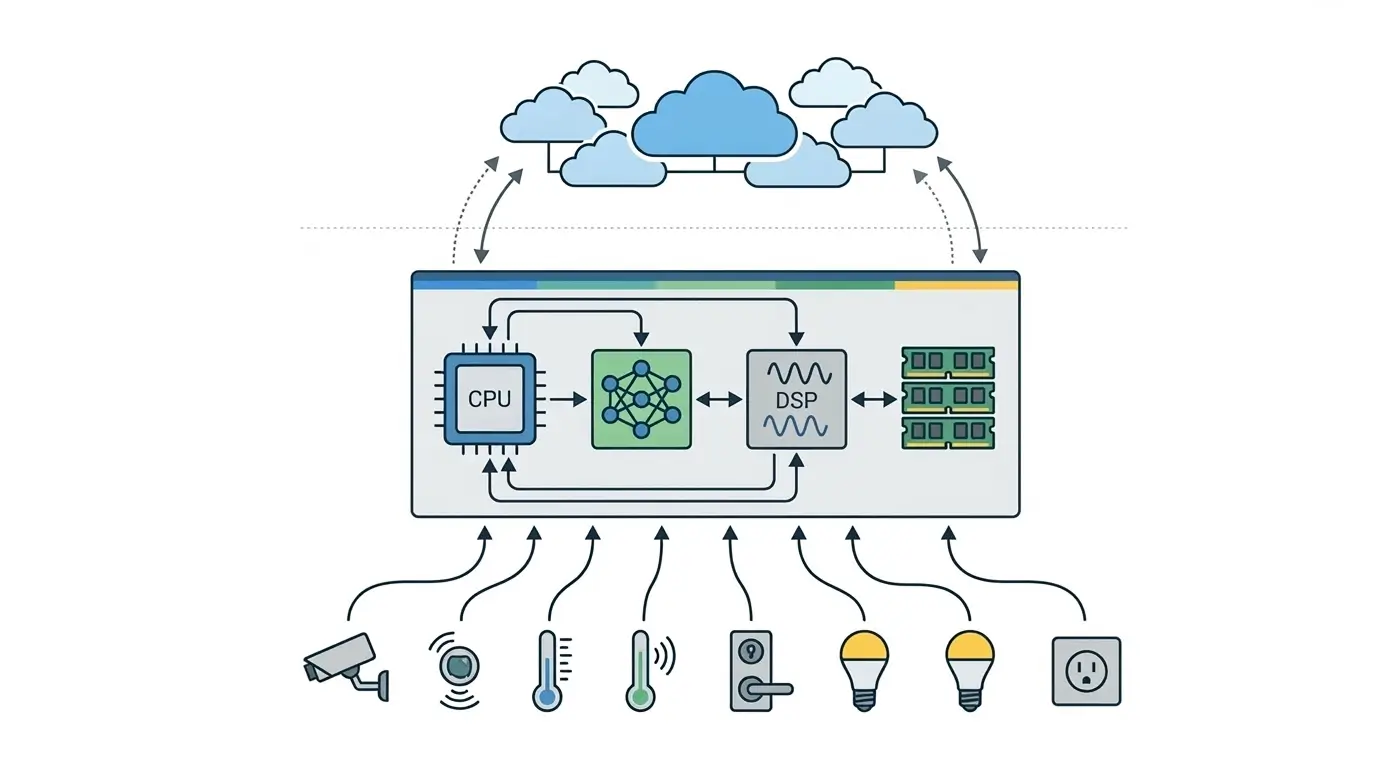
Fully Local Voice Processing (On-Device ASR/NLU/TTS) This architecture executes the entire voice interaction pipeline—from acoustic model inference (ASR) and natural language understanding (NLU) to natural language generation (NLG) and text-to-speech (TTS) synthesis—directly on the smart speaker’s embedded silicon. Its primary objective is to achieve complete data sovereignty, ensuring that sensitive user audio data never leaves the device for core AI processing. This design also targets deterministic, ultra-low latency responses, critical for applications where network variability is unacceptable, and enables full functionality even without internet connectivity. The reliance on on-device processing ensures core features remain operational even during network outages.

Hybrid Cloud-Centric Voice Processing. The hybrid model, prevalent in most commercial smart speakers, partitions AI workloads between the device and the cloud. The local device typically handles low-power, always-on tasks such as wake word detection and initial command parsing. Upon wake word activation, the captured audio stream is then transmitted to cloud-based AI services, which perform the computationally intensive ASR, NLU, and TTS. This approach leverages the vast compute and data resources of the cloud to deliver high-fidelity, broad-vocabulary AI capabilities and complex generative responses, while minimizing the local hardware footprint. Modern AI in Smart Speakers must balance edge processing and cloud-based AI inference.
Key Architectural Differences Between Local and Cloud AI
| Feature | Fully Local Voice Processing | Hybrid Cloud-Centric Voice Processing |
|---|---|---|
| Core AI Execution | On-device (dedicated NPU/DSP, CPU) | Cloud (for complex tasks), On-device (wake word, basic intent) |
| Data Flow | Audio data remains on device for core processing | Audio data streamed to cloud after wake word detection |
| Network Dependency | Minimal for core functions; required for updates/external APIs | High for core functionality; limited offline capability |
| Privacy Model | Enhanced data sovereignty; local processing minimizes exposure | Relies on cloud provider’s data governance and security protocols |
| Model Size/Complexity | Aggressively optimized (quantized, pruned), constrained | Cloud-scale, large, complex (e.g., transformer models) |
| Compute Requirements | High-performance, dedicated Neural Processing Unit (NPU) or DSP | Minimal local compute (low-power DSP/microcontroller for wake word) |
| Memory Requirements | Significant (e.g., 1-4GB LPDDR4X/5 for models/activations) | Lower (tens to hundreds of MB for OS, wake word model) |
| Storage Requirements | Substantial (e.g., 4-32GB flash for multiple models, firmware) | Lower (MBs for bootloader, OS, wake word model) |
Performance Comparison: Local vs Cloud AI
Fully Local Voice Processing: Runtime execution in a fully local architecture is characterized by deterministic, ultra-low latency. Since all inference occurs on-device, network round-trip times are eliminated, resulting in consistent response times typically in the tens to hundreds of milliseconds, bounded primarily by the NPU’s sustained throughput, memory bandwidth ceilings, and memory access latency. This architecture offers true offline functionality for its core capabilities. However, the AI model fidelity and feature breadth are inherently constrained by the on-device compute and memory budgets.
Models must be aggressively optimized (e.g., 8-bit quantization, pruning, knowledge distillation) to fit, leading to a potentially narrower vocabulary, reduced NLU accuracy for complex queries, and limited generative AI capabilities compared to cloud-scale models. Under sustained, complex voice interactions, the SoC’s thermal envelope can be challenged, potentially leading to frequency scaling or throttling, which would manifest as transient increases in response latency.
Hybrid Cloud-Centric Voice Processing: This architecture delivers high AI fidelity and broad feature sets by leveraging the virtually unlimited compute and memory resources of the cloud. Cloud-based models can be orders of magnitude larger and more complex, supporting extensive vocabularies, nuanced NLU, and advanced generative AI. However, performance is subject to variable latency, directly impacted by network conditions (bandwidth, latency, jitter) and cloud service load. Typical round-trip times can range from hundreds of milliseconds to several seconds, introducing unpredictability. Offline functionality is severely limited, generally restricted to wake word detection and possibly a few pre-programmed local commands.
Power Consumption and Thermal Behavior
Fully Local Voice Processing: The continuous execution of complex neural networks on-device results in significantly higher power consumption. Dedicated NPUs and high-bandwidth LPDDR4X/5 memory operate at elevated frequencies and power states, demanding a larger power budget for the device, often exceeding the typical few-watt sustained power envelope of many mobile and embedded platforms. This increased power dissipation translates directly into substantial thermal generation.
To maintain operational stability and prevent performance degradation from thermal throttling, robust thermal management solutions are critical. This often necessitates larger heat sinks, efficient heat pipes, and potentially active cooling mechanisms, impacting device form factor and Bill of Materials (BOM). For portable devices, this directly limits battery life.
Hybrid Cloud-Centric Voice Processing: Local power consumption is considerably lower as the device primarily performs low-power wake word detection. The main power draw comes from the Wi-Fi or cellular modem transmitting audio data. Consequently, thermal dissipation is minimal on the device itself, allowing for simpler, passive thermal solutions and smaller form factors. The bulk of the computational power and associated heat generation is offloaded to the cloud data centers.
Memory and Bandwidth Requirements
Fully Local Voice Processing: This architecture demands significant DRAM capacity and bandwidth. Large AI models (ASR, NLU, TTS) require substantial memory to store model weights, intermediate activations, and runtime buffers. Capacities of 1-4GB LPDDR4X/5 are common, necessitating high-speed memory controllers and wide bus interfaces to prevent memory bottlenecks. Continuous inference places sustained memory pressure, requiring efficient memory management by the embedded operating system and hardware-level cache optimization. On-chip storage (e.g., 4-32GB eMMC or UFS flash) is also substantially larger to accommodate multiple model versions, language packs, and complex firmware. High-speed interconnects (e.g., AXI, NoC) are crucial for efficient data transfer between the CPU, NPU, and DRAM, impacting sustained performance.
Hybrid Cloud-Centric Voice Processing: Local memory requirements are substantially lower. The device only needs enough DRAM (tens to hundreds of MB) for the operating system, wake word model, and network buffers. Local storage (MBs of flash) is primarily for the bootloader, OS image, and the wake word model. Bandwidth requirements between local components are minimal, as complex data processing is offloaded. The primary bandwidth concern shifts to the network interface for efficient audio streaming to the cloud, directly influencing latency behavior.
Software Ecosystem and AI Development Tools
Fully Local Voice Processing: The software ecosystem for fully local AI is highly specialized and fragmented. It relies on on-device AI frameworks optimized for specific NPUs (e.g., custom TensorFlow Lite runtimes, ONNX Runtime with hardware acceleration, proprietary model compilers). MLOps (Machine Learning Operations) for edge devices is significantly more complex and challenging. Model updates and new features require intricate firmware update mechanisms, often involving over-the-air (OTA) updates that must be robust, secure, and atomic. This leads to slower iteration cycles and higher development costs due to the need for deep embedded systems expertise and hardware-aware AI optimization.
Hybrid Cloud-Centric Voice Processing: This architecture leverages mature, scalable cloud MLOps platforms (e.g., AWS SageMaker, Google AI Platform, Azure ML). Model development, training, deployment, and A/B testing occur in the cloud, enabling rapid iteration and feature velocity. Updates and improvements to the core AI models are deployed seamlessly in the cloud, often without requiring device-side firmware updates. The device-side software stack is simpler, focusing on audio capture, network communication, and basic local command processing.
Real-World Deployment
Fully Local Voice Processing: Deployment targets premium price tiers due to the significantly higher Bill of Materials (BOM) for powerful silicon, increased memory, and robust thermal solutions. It appeals to niche markets prioritizing absolute privacy on-device AI, data sovereignty, and guaranteed offline functionality (e.g., secure enterprise environments, specific regulatory regions). Regulatory compliance for data handling is simplified by keeping data on-device, but firmware security and update integrity become paramount. Scaling new features or improving model accuracy is inherently limited by the individual device’s hardware capabilities and the complexity of embedded MLOps.
Hybrid Cloud-Centric Voice Processing: This design enables mass market adoption due to its lower device BOM. It offers a broader, more dynamic feature set and can rapidly integrate new AI advancements. However, it introduces complex regulatory and data governance challenges related to cloud data storage, cross-border data transfer, and compliance with various privacy regulations (e.g., GDPR, CCPA). Scalability is achieved through the cloud infrastructure, allowing for millions of concurrent users and continuous AI model improvements.
Which Architecture Is More Efficient?
The “efficiency” of each design is contingent upon the specific performance metric and product strategy.
- Compute Efficiency (per query): For simple, deterministic, low-latency tasks, fully local processing is highly efficient as it avoids network overhead. For complex, broad-domain queries, the hybrid cloud model is more efficient, leveraging shared, highly optimized cloud-scale resources that would be impractical to embed.
- Cost Efficiency (BOM): Hybrid cloud is significantly more cost-efficient for device manufacturing, enabling lower retail prices and mass-market penetration. Fully local designs incur a substantially higher BOM.
- Operational Cost (TCO): Hybrid cloud incurs ongoing cloud service costs (compute, storage, bandwidth). Fully local has higher upfront device costs but lower ongoing data transmission expenses for core functions.
- Privacy Efficiency: Fully local is inherently more efficient at preserving data sovereignty by minimizing data egress.
- Energy Efficiency (device level): Hybrid cloud is more energy-efficient on the device, as the most power-intensive computations are offloaded.
Therefore, neither design is universally “more efficient.” The optimal choice is a strategic engineering decision driven by the product’s core value proposition, target market, and the acceptable trade-offs across privacy, performance, cost, and feature velocity.
Key Takeaways
The choice between fully local and hybrid cloud AI architectures in smart speakers represents a fundamental trade-off between silicon constraints, runtime execution characteristics, and system-level objectives. Fully local processing prioritizes data sovereignty and deterministic, ultra-low latency, demanding high-performance NPUs, substantial memory, and robust thermal management, leading to a higher BOM and constrained AI model fidelity.
Conversely, the hybrid approach leverages scalable cloud resources for complex AI, enabling broader feature sets and lower device costs, but introduces network dependency and inherent data transmission. Ultimately, the architectural decision is a strategic one, balancing engineering feasibility with product requirements for privacy, responsiveness, feature richness, and market accessibility. The evolution of AI in Smart Speakers will likely continue toward hybrid architectures combining edge AI and cloud intelligence.