Table of Contents
On-device AI powers truly private voice assistants by processing voice commands locally on the device using dedicated AI hardware such as DSPs and NPUs. Instead of sending audio data to cloud servers, speech recognition and natural language understanding happen on-device, ensuring better privacy, lower latency, faster response times, and offline voice functionality.
Voice assistants have become common, offering significant convenience. However, the architecture of many popular voice assistants, which relies on sending raw audio data to cloud servers for processing, has raised significant privacy concerns. Users are rightly apprehensive about their conversations being recorded, stored, and potentially analyzed off-device. Addressing this privacy dilemma requires integrating AI directly into the device’s silicon, enabling robust, high-performance voice processing while significantly enhancing user data privacy. This approach defines how on-device AI powers truly private voice. This shift explains why on-device AI powers truly private voice assistants across modern smartphones, wearables, and smart home devices focused on privacy-first AI computing. Modern voice systems rely on edge AI for voice and advanced on-device speech processing to deliver secure and low-latency assistant experiences.
What It Is: How On-Device AI Powers Truly Private Voice
On-device AI for private voice describes a device’s ability to execute all essential artificial intelligence computations—specifically for voice recognition and understanding—entirely within its local hardware. This encompasses tasks such as wake word detection, automatic speech recognition (ASR), and natural language understanding (NLU). The fundamental principle is that sensitive, personal raw audio data is processed, transcribed, and interpreted directly on the device, without transmission to external cloud servers. This approach stands in stark contrast to traditional cloud-centric voice assistants, which upload audio streams for remote processing.
How On-Device AI Powers Truly Private Voice Assistants Work
The process of on-device private voice relies on specialized hardware and optimized AI models:
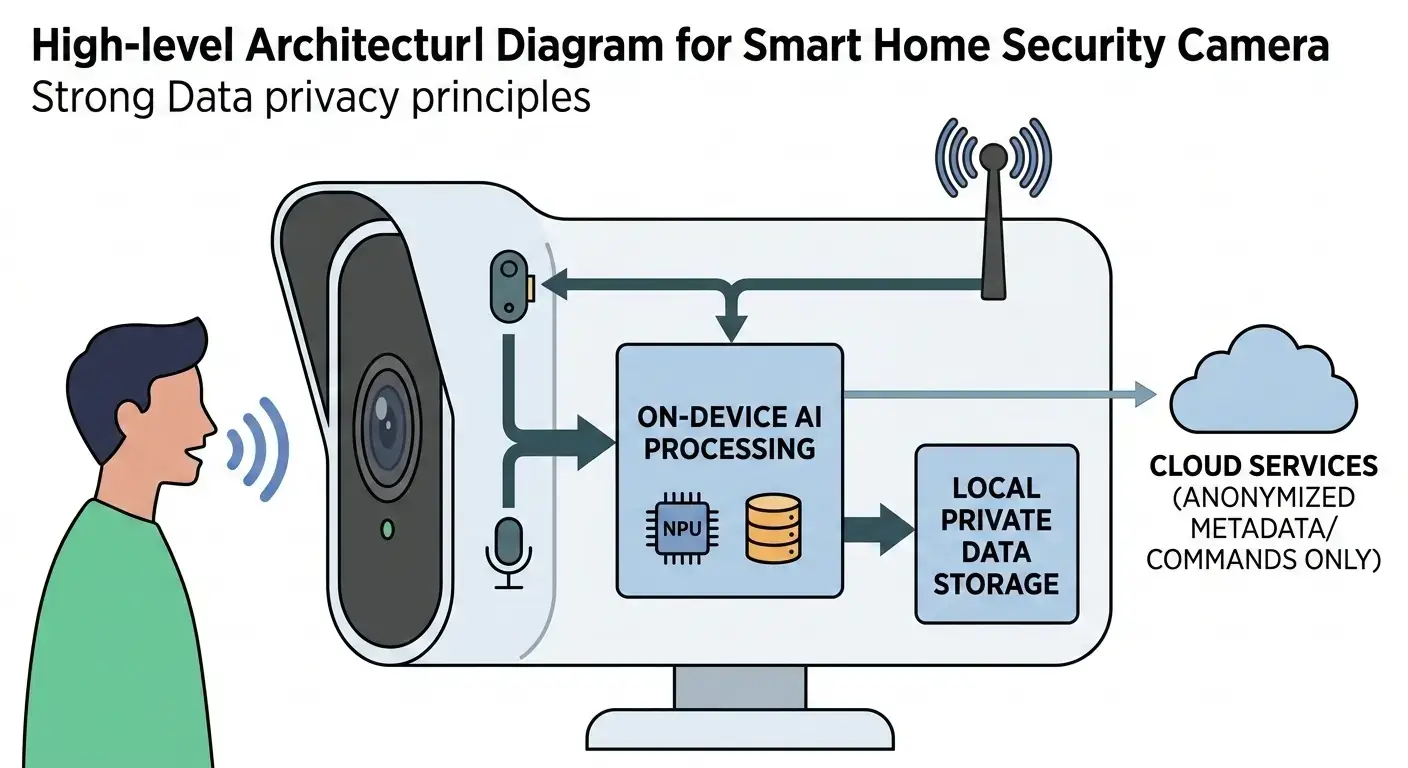
- Local Wake Word Detection: A low-power, always-on Digital Signal Processor (DSP) continuously monitors a small audio buffer for a specific wake word (e.g., “Hey Siri,” “Alexa”). This DSP executes a highly optimized, small neural network model, consuming minimal power. Crucially, this initial audio processing occurs entirely on the device, preventing any raw audio data from leaving it.
- Activation and Full ASR: Upon wake word detection, the system activates higher-power components, typically a dedicated Neural Processing Unit (NPU) or AI accelerator, operating within the device’s power envelope. The captured audio stream is then fed through the on-device Automatic Speech Recognition (ASR) model. This model, often a highly optimized Conformer or Transformer-based architecture, converts acoustic features into a text transcript locally.
- On-Device Natural Language Understanding (NLU): The transcribed text is immediately passed to an on-device NLU model. This model, frequently a compressed variant of larger architectures like BERT, processes linguistic patterns to perform intent recognition (e.g., “set timer,” “play music”) and entity extraction (e.g., “5 minutes,” “jazz”). All linguistic processing occurs within the device’s secure hardware boundaries.
- Local Command Execution and Response: For a wide range of commands, the device executes the action directly based on the local NLU output (e.g., setting an alarm, controlling local smart home devices). If a spoken response is required, an on-device Text-to-Speech (TTS) model synthesizes the audio, ensuring the entire interaction loop remains local.
This comprehensive data flow ensures that raw audio data from general conversation is not transmitted from the device. Only highly specific, non-identifiable text queries or anonymized metadata, meticulously designed for privacy, might be sent to the cloud for complex queries, typically encrypted and subject to explicit user consent. This nuanced approach highlights the ongoing debate and architectural considerations involved in On-device AI vs Cloud AI for various applications.
Architecture Overview
Modern hardware innovation explains how on-device AI powers truly private voice experiences by combining DSPs, NPUs, and optimized neural models within a single System-on-Chip architecture.
| Attribute | Details |
|---|---|
| Primary Function | Enabling private, low-latency voice processing on-device |
| Execution Location | On-device (edge) |
| Latency Profile | Ultra-low (microseconds to milliseconds) |
| Power Envelope | Milliwatts for always-on, low-watts for active inference |
| Typical Silicon | NPU, DSP, MCU, or dedicated accelerator |
| Key Constraint | Memory bandwidth, thermal headroom, sustained power delivery |
The hardware architecture underpinning private voice exemplifies heterogeneous computing, integrating specialized processing units within a System-on-Chip (SoC) to achieve high performance and low power.
System-on-Chip (SoC) Integration: Modern private voice solutions are built upon highly integrated SoCs that combine various processing units. This design minimizes data movement and latency, which is crucial for real-time voice processing within a constrained power envelope.

Core Processing Units:
- Central Processing Unit (CPU): The CPU handles the operating system, application logic, control flow, and less computationally intensive or sequential parts of the AI pipeline, such as pre-processing, post-processing, and beam search in ASR decoding. Examples include ARM Cortex-A series or custom designs.
- Digital Signal Processor (DSP): Specialized for efficient, low-power audio processing, the DSP performs tasks like noise reduction, echo cancellation, acoustic feature extraction (e.g., MFCCs), and the critical always-on wake word detection. DSPs like Qualcomm Hexagon or Cadence Tensilica HiFi are optimized for fixed-point arithmetic and parallel signal processing, operating within milliwatt power budgets for sustained operation. Developers can leverage specialized toolchains and SDKs, such as the Qualcomm AI Engine SDK documentation, to optimize models for these heterogeneous architectures.
- Neural Processing Unit (NPU) / AI Accelerator: This serves as the primary compute engine for deep learning inference. Dedicated hardware, such as Apple Neural Engine or Google Edge TPU, comprises MAC units, often arranged in systolic arrays. These specialized units are at the forefront of AI acceleration, a competitive landscape further explored in comparisons like Snapdragon X Elite vs Intel AI Boost vs AMD XDNA. NPUs are optimized for matrix multiplications and convolutions, supporting quantized integer data types (INT8, INT4) to reduce memory footprint and increase efficiency. They typically include dedicated on-chip memory (scratchpads) to minimize latency. For mobile applications, NPUs generally operate within a few watts for sustained inference, with peak performance subject to thermal constraints.
- Graphics Processing Unit (GPU): While less common as a primary AI accelerator for voice due to power efficiency considerations, GPUs can accelerate some neural network operations, particularly those benefiting from floating-point precision or larger batch sizes, or in systems lacking a dedicated NPU.
Memory Hierarchy:
- NPU/DSP Scratchpad Memory (SRAM): This dedicated, fast on-chip memory is directly controlled by the NPU/DSP. It stores neural network weights, biases, and intermediate activations for current layers, thereby minimizing power-intensive external DRAM access. This is crucial for achieving high inference throughput.
- System RAM (DRAM): Low-Power Double Data Rate (LPDDRx) synchronous dynamic RAM serves as off-chip memory, storing neural network model weights, larger intermediate activations, and general application data. Memory bandwidth limitations here can become a critical bottleneck for larger models or higher throughput requirements.
- Flash Storage: NAND-based storage (e.g., UFS, eMMC) holds persistent model files and system software, which are loaded into DRAM as needed.
Bandwidth Considerations: High-speed on-chip interconnects (e.g., ARM AMBA AXI) link all components, facilitating efficient data transfer. The bandwidth between the NPU/DSP and its scratchpad is typically very high, enabling rapid data access. Critically, quantization (e.g., INT8, INT4) significantly reduces data size, thereby lowering bandwidth requirements and power consumption for data movement between the NPU/DSP and System RAM. On-device models are highly optimized (pruned, quantized, distilled) to fit within these memory and bandwidth constraints, typically ranging from tens to hundreds of megabytes.
Performance Benefits of On-Device AI for Truly Private Voice
The shift to on-device AI for voice brings several key performance advantages:

- Low Latency: By eliminating the round-trip to the cloud, on-device processing significantly reduces latency. This results in a more responsive and natural user experience, with commands executed with minimal delay.
- High Throughput: Dedicated NPUs and DSPs are designed for parallel execution of neural network operations, enabling high inference throughput for complex ASR and NLU models, depending on model architecture and quantization. Quantization to INT8 or even INT4 further boosts effective throughput by allowing more operations per clock cycle and reducing data movement.
- Enhanced Power Efficiency: Specialized hardware accelerators are engineered for energy efficiency. DSPs operate in milliwatt ranges for continuous wake word detection, while NPUs perform complex inferences with significantly lower power consumption than general-purpose CPUs or GPUs for the same task, especially for optimized models. This is critical for battery-powered devices within strict power envelopes.
- Reliability and Offline Capability: On-device processing allows voice assistants to remain functional for many core commands even without an internet connection, enhancing reliability and usability in various environments.
- Model Optimization: Performance is heavily reliant on highly optimized models. Techniques like quantization, pruning, and knowledge distillation are applied to reduce model size and computational complexity, allowing them to run efficiently on resource-constrained embedded hardware while maintaining accuracy within defined parameters. This meticulous optimization is fundamental to how on-device AI powers truly private voice, ensuring both efficiency and privacy.
- These improvements clearly show how on-device AI powers truly private voice assistants with faster and more reliable real-time interaction.
Real-World Applications
On-device AI for private voice is a deployed technology, integrated into various consumer and industrial products:
- Smartphones and Tablets: Apple’s Neural Engine in A-series and M-series Bionic chips, Google’s Tensor SoCs, and Qualcomm’s AI Engine (integrating Hexagon NPU/DSP) enable private voice assistants like Siri and Google Assistant to perform ASR and NLU locally for many common commands, all within the device’s power budget. Further technical details on optimizing AI workloads for Qualcomm platforms can be found in the Qualcomm AI Engine SDK documentation.
- Smart Speakers and Displays: Devices from companies like Amazon (Echo), Google (Nest Hub), and Apple (HomePod) increasingly leverage on-device processing for wake word detection and basic commands, thereby minimizing cloud interaction. This blend of local and remote processing is also critical for enhancing privacy and performance in other domains, such as understanding How Hybrid On-Device and Cloud AI Improves Smart Home Cameras.
- Wearables: Smartwatches and hearables utilize ultra-low-power DSPs and NPUs to enable always-on wake word detection and quick command execution, optimizing battery life and avoiding the transmission of sensitive audio to the cloud.
- Automotive Infotainment Systems: In-car voice assistants can process commands locally for navigation, media control, and climate adjustments, enhancing privacy and maintaining functionality even in areas with poor connectivity, depending on the specific command.
- Industrial and Edge Devices: For applications requiring high security and low latency, such as smart factory controls or medical devices, on-device voice AI provides a robust solution for human-machine interaction without direct data exposure.
Limitations
Today, on-device AI powers truly private voice assistants in smartphones, smart speakers, automotive systems, and next-generation IoT devices. Despite its significant advantages, on-device AI for private voice presents certain limitations:
- Model Size and Complexity: While optimization techniques are powerful, a practical limit exists on how large and complex a model can be while fitting on-device and maintaining real-time performance within power and thermal constraints. This can restrict vocabulary breadth or understanding depth compared to massive cloud-based models.
- Hardware Requirements: Implementing truly private voice necessitates specialized hardware (NPUs, powerful DSPs), which contributes to Bill of Materials (BOM) cost and design complexity. Not all embedded systems can accommodate these requirements, particularly those with extreme cost or size constraints.
- Model Updates and Personalization: Updating on-device models can be more challenging than updating cloud models. Personalization (e.g., adapting to a user’s accent or vocabulary) is also more difficult to implement purely on-device without local, privacy-preserving learning or occasional, carefully managed cloud interaction for model refinement.
- Long-Tail Queries: For highly obscure queries, complex factual questions, or tasks requiring real-time access to vast, frequently updated external databases (e.g., current events, niche knowledge), a cloud connection often remains necessary. The challenge lies in sending only anonymized, non-identifiable data, subject to strict privacy protocols.
- Development Complexity: Optimizing AI models for specific embedded hardware architectures and managing heterogeneous computing environments demands specialized expertise in both AI and embedded systems engineering, thereby increasing development overhead.
Why On-Device AI Powers Truly Private Voice Assistants Matter
On-device AI for private voice represents a critical advancement for several key reasons:
- Enhanced Privacy and Security: By keeping raw audio data local, this approach significantly mitigates risks of unauthorized access, data breaches, or misuse by third parties. Users gain greater assurance that their conversations remain private.
- Increased User Trust: In an era of increasing data privacy concerns, offering a demonstrably private voice assistant builds significant trust with users, differentiating products in a competitive market.
- Reduced Latency and Improved Responsiveness: Local processing translates to faster response times, leading to a smoother, more natural, and less frustrating user experience.
- Offline Functionality: Devices can operate independently of an internet connection for core commands, enhancing their reliability in areas with poor or no connectivity or during network outages.
- Lower Bandwidth Consumption: Minimizing the need to stream audio to the cloud significantly reduces network bandwidth usage, which can be beneficial for mobile data plans and overall network load.
- Edge Computing Enablement: This technology pushes AI capabilities to the “edge,” enabling intelligent decision-making closer to the data source. This is crucial for IoT, industrial automation, and autonomous systems, especially where real-time processing and data locality are paramount.
Key Takeaways
- On-device AI powers truly private voice assistants by keeping sensitive audio processing local, minimizing cloud dependency while improving privacy, speed, and reliability.
- Achieved through heterogeneous SoC architectures, integrating specialized CPUs, DSPs, and NPUs.
- DSPs handle low-power wake word detection; NPUs accelerate full ASR and NLU inference, subject to power and thermal constraints.
- Model optimization techniques (quantization, pruning) are essential for fitting complex AI models onto embedded hardware while maintaining performance.
- Key benefits include enhanced privacy, lower latency, improved power efficiency, and offline functionality for core tasks.
- While offering significant advantages, limitations exist in model complexity, hardware cost, and cloud interaction for highly complex or dynamic queries.
- Ultimately, on-device AI is crucial for building trust and delivering a secure, responsive, and reliable voice interaction experience.
- As adoption grows, on-device AI powers truly private voice assistants while maintaining strong privacy protections and offline usability.
Frequently Asked Questions
How does on-device AI improve voice assistant privacy?
On-device AI improves privacy by processing voice data locally instead of transmitting recordings to cloud servers.
Do private voice assistants work offline?
Yes, on-device AI enables many voice commands to function without internet connectivity.


