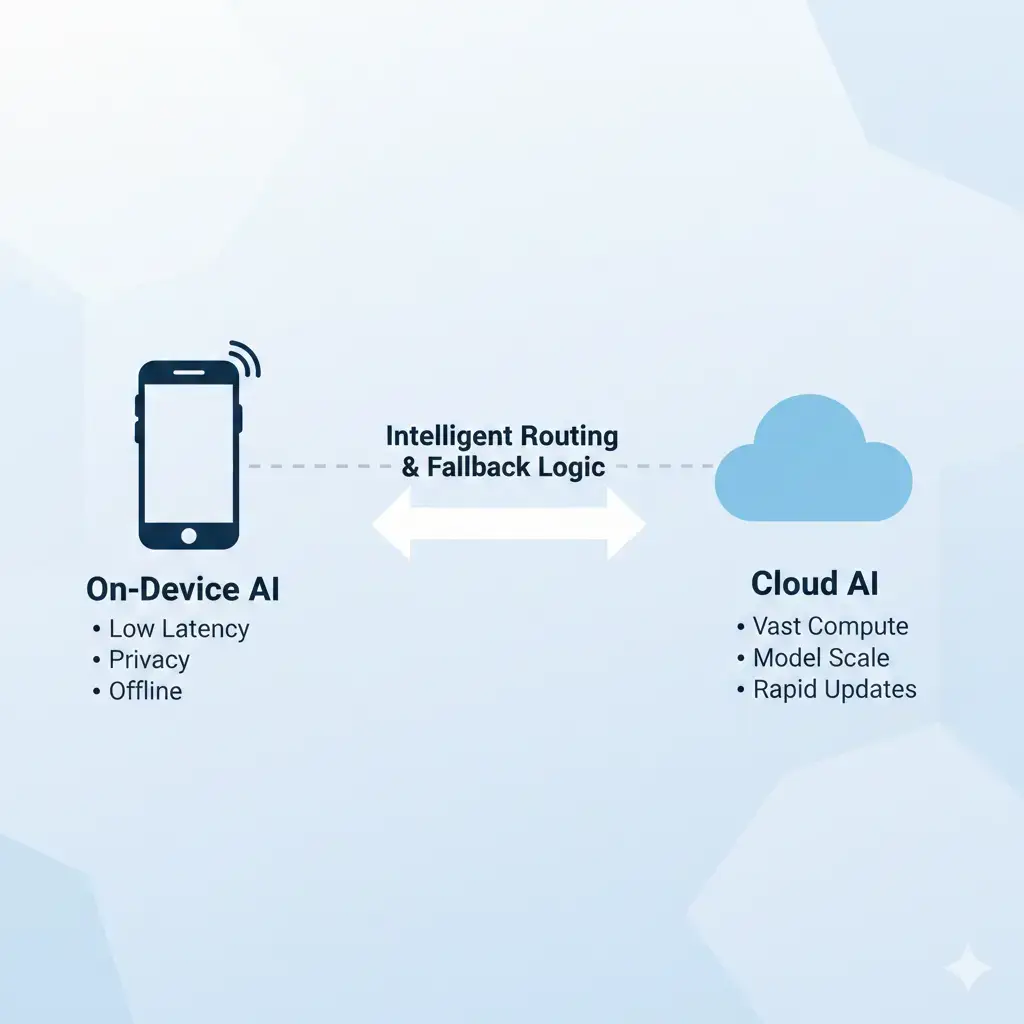
On-Device AI Cloud Fallback enables low-latency, private, and offline AI experiences while working within strict power, thermal, and memory limits. When these limits are reached, On-Device AI Cloud Fallback allows systems to route tasks to the cloud, forming a hybrid AI architecture.
Table of Contents
The seamless removal of a background object from a photo on a flagship phone, or a voice assistant transcribing a meeting with minimal latency, even while offline, can feel like magic. These moments demonstrate the capabilities of on-device AI and the role of On-Device AI Cloud Fallback when local limits are reached. Yet sustaining such complex operations locally frequently pushes against a device’s power envelope and thermal dissipation limits, underscoring the architectural constraints inherent to mobile hardware.
In practice, On-Device AI Cloud Fallback allows devices to extend capability beyond local hardware limits without exposing these transitions to users. Many of these seemingly local computations involve a coordinated interaction between on-device models and remote servers. This is particularly true for large, general-purpose AI models, which often exceed the practical memory and sustained compute capacity of even high-end smartphones.
On-Device AI Cloud Fallback is a hybrid execution strategy that dynamically routes AI tasks between local hardware and cloud infrastructure, bridging the gap between on-device AI vs cloud AI execution models.
This orchestration aims to maintain a seamless user experience by leveraging low-latency local execution where possible, while relying on cloud resources when device constraints are reached. The model exists as a direct consequence of physical design limits, balancing edge efficiency with cloud-scale capability.
These limits typically include finite power budgets, thermal dissipation capacity, memory capacity, and memory bandwidth, which together define the practical boundaries of On-Device AI Cloud Fallback.
Why This Matters
For engineers and developers, understanding On-Device AI Cloud Fallback is essential when designing AI features that must operate across diverse hardware conditions. This hybrid execution model has significant implications across the technology stack. For engineers and developers, understanding fallback behavior is essential. It highlights the core trade-offs between privacy, responsiveness, and offline operation—key strengths of on-device AI—versus the scale, model complexity, and update velocity enabled by cloud infrastructure.
From a user perspective, the approach aims to provide consistent functionality even when local resources are constrained. However, it also introduces variability in latency, privacy guarantees, and feature availability depending on device state and connectivity.
How the System Works
At a system level, hybrid AI execution depends on continuously deciding where inference should occur. This decision is dynamic rather than fixed and is influenced by real-time signals such as CPU, GPU, and NPU load; temperature; battery state; available memory; and network conditions.
Monitoring these parameters is critical for preventing thermal throttling, managing limited power budgets, and avoiding memory exhaustion. These are not transient performance issues but architectural boundaries of compact, passively cooled devices. On modern platforms, this resource monitoring and model dispatch is handled through system-level machine learning frameworks, such as Android’s Neural Networks API (NNAPI), which abstract hardware capabilities and availability for AI workloads.
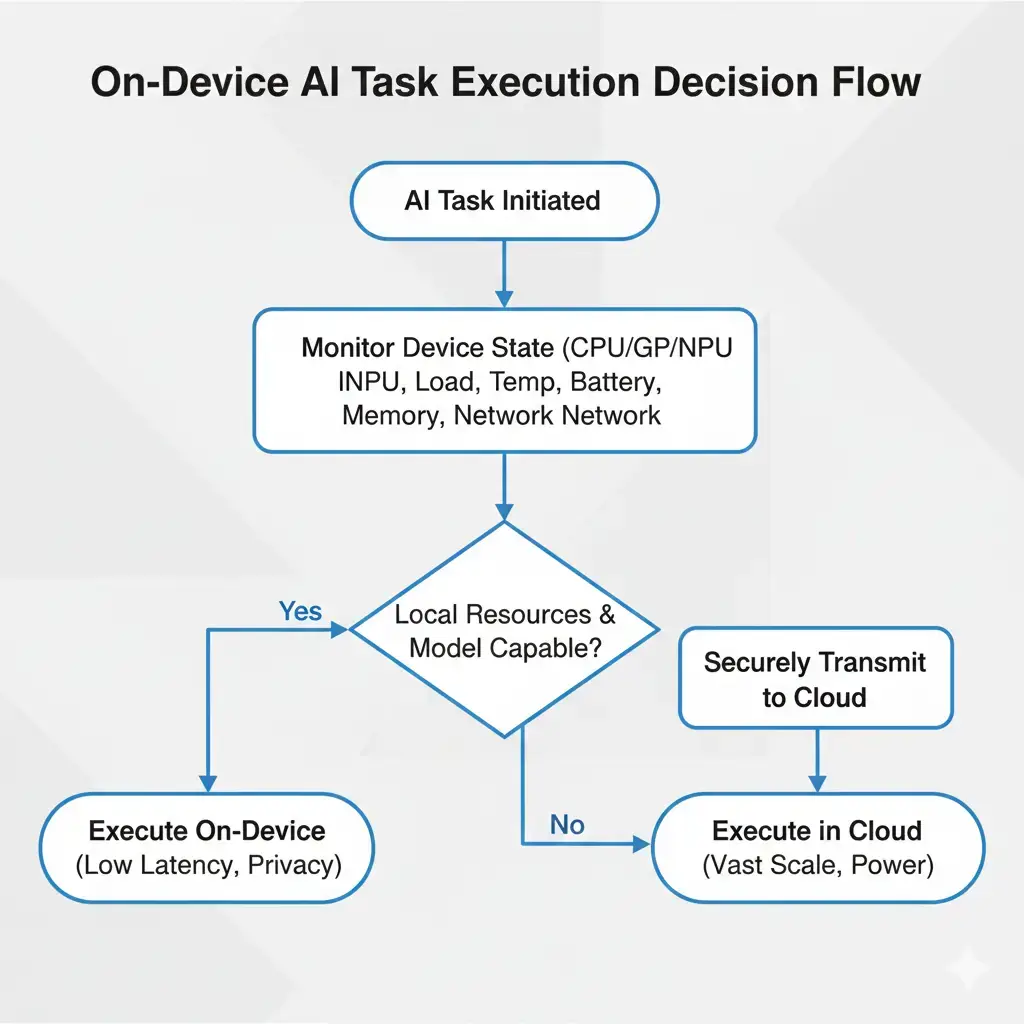
When an AI task is initiated, On-Device AI Cloud Fallback logic typically prioritizes on-device execution. If the local model is capable and sufficient headroom exists—power, thermal, and memory—the task executes locally, favoring low latency and data locality. In practice, this generally means fitting within a few watts of sustained power and the device’s available RAM.
If these conditions are not met—due to model size, memory pressure, elevated temperatures, or battery constraints—the system may initiate a silent fallback. In such cases, part or all of the task is securely transmitted to the cloud infrastructure for execution.
This routing treats the local model as a low-latency, privacy-preserving cache for common workloads, while the cloud serves as a high-capability backend for more demanding or infrequent requests.
Hardware Architecture Overview
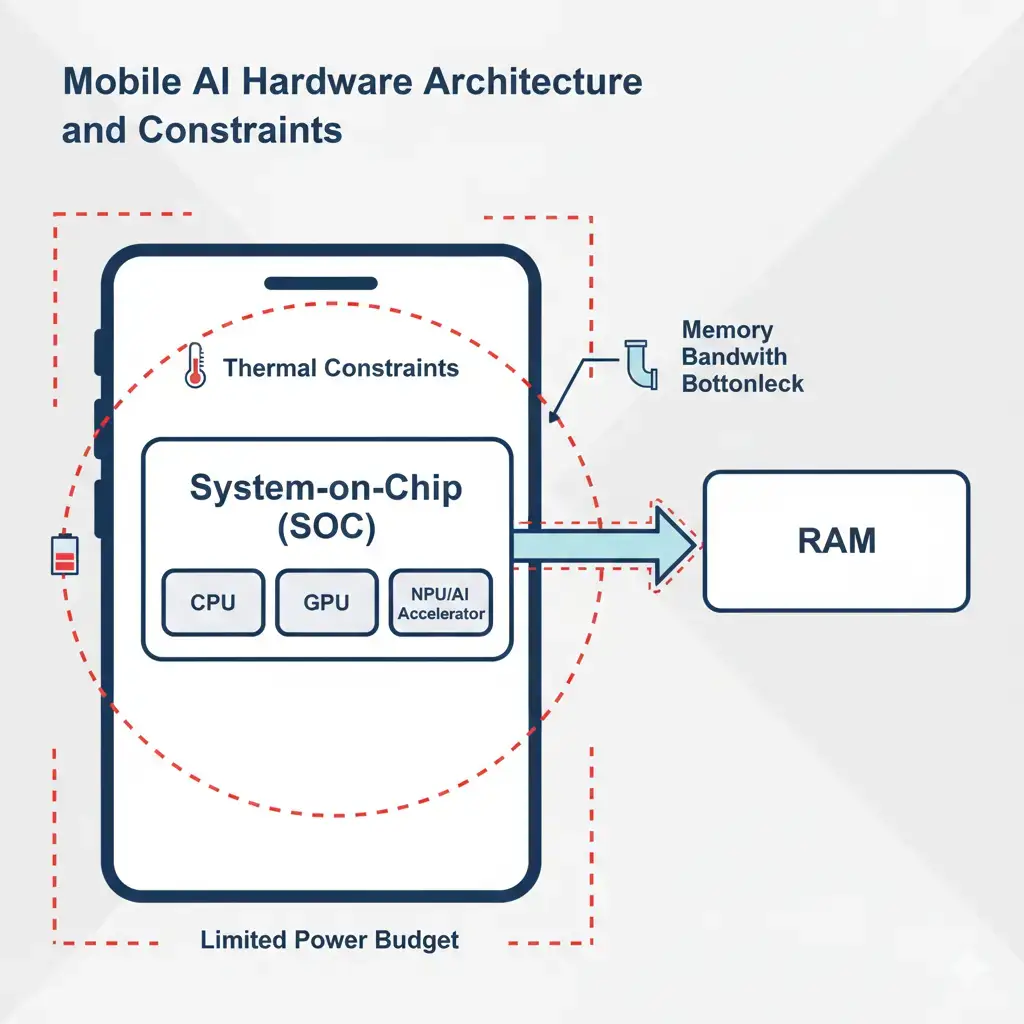
Modern on-device AI systems are constrained not by a single component, but by the interaction between compute units and shared system resources. The CPU, GPU, and NPU reside within a common system-on-chip (SoC) and compete for a limited power budget, thermal headroom, and memory bandwidth. While NPUs are optimized for energy-efficient inference, they remain dependent on system RAM for model weights and intermediate data. When memory bandwidth is saturated, thermal limits are reached, or sustained power draw exceeds design thresholds, local inference performance degrades. At this point, On-Device AI Cloud Fallback becomes a system-level mechanism, offloading workloads that exceed the device’s physical limits to cloud infrastructure.
The table below outlines the primary hardware components involved in on-device AI and their typical roles:
| Component | Primary Role in On-Device AI | Typical Performance Impact |
|---|---|---|
| CPU | General-purpose ML, fallback | Less efficient, higher power consumption for ML workloads |
| GPU | Parallel ML tasks, larger models | Adept at parallel processing for larger models, though more power-intensive than NPUs |
| NPU/AI Accelerator | Dedicated, energy-efficient ML | High efficiency, lower power, specific ML operations |
| RAM | Stores model weights & activations | Limits model size, impacts latency if insufficient |
- While versatile, the CPU is generally less efficient for the highly parallel computations demanded by ML models.
- Purpose-built for AI, NPUs (Neural Processing Units) offer superior energy efficiency and throughput for common ML operations such as matrix multiplication, forming the basis of on-device machine learning frameworks used across modern mobile platforms. However, even these specialized units typically exhibit a significant gap between their theoretical peak performance and what they can sustain under continuous thermal and power limits. This gap highlights the practical, architectural limitations imposed by heat dissipation and available power during real-world operation, emphasizing that peak TOPS figures rarely translate directly to sustained throughput on edge devices.
- RAM is a critical resource in On-Device AI Cloud Fallback, directly limiting the size of AI model parameters and intermediate data that can be loaded and processed locally. Most flagship smartphones currently offer 8GB to 16GB of RAM, which directly constrains the size of on-device models. Crucially, memory bandwidth—the rate at which data can be read from or written to memory—is also a critical factor, as moving large model parameters and intermediate data quickly is essential for low latency. This is a fundamental system-level constraint, often a greater bottleneck than raw compute power for many on-device AI workloads.
Performance and Latency Constraints
A primary advantage of on-device AI is its ability to deliver very low latency, a factor often crucial for real-time user experiences like voice assistants or live camera filters. Local processing eliminates network delays. However, sustaining this performance on a compact device presents significant hurdles:
- Thermal Throttling: Intensive AI workloads inevitably generate heat. To prevent overheating, devices reduce clock speeds, directly increasing inference latency. This throttling can occur within minutes for demanding tasks, significantly impacting sustained performance.
- Memory Bandwidth: Moving large model parameters and intermediate data between RAM and processing units often becomes a bottleneck, particularly for complex models. High memory bandwidth is crucial for efficient data transfer, yet it remains a finite resource on mobile platforms.
- NPU Peak vs. Sustained Performance: While NPUs boast impressive peak FLOPs (Floating Point Operations Per Second), their sustained performance frequently degrades under continuous load due to thermal and power limits. In contrast, cloud-based AI benefits from vast compute resources and active cooling, enabling the execution of large and complex models at high speeds. This stark difference in available hardware resources fundamentally shapes the balance between edge and cloud AI capabilities. Nonetheless, network latency (typically tens to hundreds of milliseconds) is an unavoidable overhead, rendering it unsuitable for ultra-low-latency applications.
Power, Thermal, and Memory Limits
Fundamentally, the physical constraints of consumer devices are the primary drivers of AI phone cloud dependency. These are not merely performance bottlenecks; rather, they represent hard, architectural ceilings on what can be achieved locally.
- Power Consumption: Running computationally intensive AI models rapidly depletes battery life. While NPUs are designed for efficiency, complex tasks nonetheless demand significant power. Most mobile devices are designed for a sustained power envelope of only a few watts for general computation—the maximum power a device can continuously draw without overheating or rapidly draining the battery—with brief bursts allowed for peak performance. This power budget is a core architectural decision, dictating the practical limits of on-device AI. Consequently, a typical smartphone battery (e.g., 4000-5000 mAh) can only sustain high-intensity AI for limited durations.
- Thermal Management: Sustained computation generates heat requiring effective dissipation. As most mobile devices rely on passive cooling (i.e., no fans), exceeding thermal thresholds triggers throttling, reducing performance to prevent hardware damage.
- Memory Availability: AI models, particularly large language models (LLMs) or large vision models (LVMs), require substantial RAM to store their parameters (learned values) and intermediate activations (data generated at each layer during processing) during inference. This is a crucial constraint, as most flagship smartphones currently offer 8GB to 16GB of RAM, directly limiting the size of on-device models. Insufficient memory availability can necessitate a model’s partial or full offload to the cloud.
These constraints often manifest as:
- Insufficient RAM (e.g., 8GB-16GB in flagship phones) to load models with billions of parameters (a 7B parameter LLM might require ~14GB of RAM in FP16 precision).
- Rapid battery drain when AI features are heavily used.
- Noticeable performance degradation or stuttering as the device throttles under load.
Real-World Trade-Offs
Implementing on-device AI with cloud fallback invariably involves an engineering compromise, balancing several competing priorities, all ultimately rooted in the physical hardware constraints of edge devices.
- Privacy vs. Model Scale/Accuracy: While keeping sensitive data on-device maximizes privacy, it inherently limits access to the most advanced, often cloud-hosted, models with billions or trillions of parameters. These massive models simply cannot fit within the memory and computational constraints of a mobile device, making privacy a key trade-off directly influenced by hardware limitations.
- Latency vs. Computational Complexity: Achieving ultra-low latency demands smaller, highly optimized on-device models, which may, in turn, sacrifice accuracy or the ability to handle complex, nuanced queries.
- Battery Life vs. Sustained AI Workloads: Running intensive AI tasks locally offers immediate results but can significantly reduce battery endurance, compelling developers to choose between capability and longevity. Sustained high-power AI workloads quickly exceed the mobile device’s thermal and power envelope, leading to rapid battery depletion.
- Development/Optimization Effort vs. Device Coverage: Optimizing a single complex ML model for efficient execution across the diverse hardware configurations and operating systems of various consumer devices is a significant, costly endeavor.
- Model Freshness vs. On-Device Update Cycles: Cloud models benefit from daily or hourly updates, enabling rapid iteration and bug fixes. In contrast, on-device models typically require full application or OS updates, a much slower process.
Edge vs Cloud Considerations
In practice, On-Device AI Cloud Fallback ensures that the choice between edge and cloud execution is rarely absolute; most advanced AI features today embrace a hybrid model.
Edge (On-Device) AI:
- Advantages: Enhanced privacy (data processing can remain local), very low latency, offline functionality, reduced bandwidth usage, and potentially better power efficiency for specific tasks.
- Disadvantages: Limited computational power, memory, and thermal headroom; constrained model size and complexity; slower model update cycles.
Cloud AI:
- Advantages: Vast compute resources, ability to run large and complex models (e.g., large foundation models), rapid model updates, centralized data for continuous improvement.
- Disadvantages: Requires network connectivity, introduces network latency, potential privacy concerns (data leaves the device), and bandwidth costs.
Ultimately, the hybrid approach intelligently routes tasks, leveraging the edge for its strengths (real-time, private, offline), which are defined by its hardware capabilities, and the cloud for its capabilities (scale, complexity, rapid iteration).
Future Direction
Progress in on-device AI will depend on hardware–software co-design. Likely developments include more specialized NPUs, improved memory architectures, and continued advances in quantization, sparsity, and selective execution techniques.
Rather than eliminating cloud fallback, future systems are expected to make it increasingly transparent through predictive resource management and finer-grained task partitioning.
Key Takeaways
- On-device AI offers significant benefits in terms of privacy, latency, and offline capability, but it inherently operates within strict power, thermal, and memory constraints.
- On-Device AI Cloud Fallback is an essential engineering strategy, enabling devices to offload complex or resource-intensive AI tasks to powerful remote servers when local limitations are met.
- This hybrid approach involves inherent trade-offs between performance, privacy, battery life, and the scale of AI models that can be deployed.
- Future advancements in both hardware and software aim to expand the capabilities of on-device AI, enabling more complex models to run efficiently at the edge by pushing the boundaries of device limits, while contributing to a seamless user experience through intelligent cloud fallback.


