Table of Contents
Introduction
NPU in smartphones is transforming how mobile devices handle artificial intelligence. Instead of relying only on CPUs and GPUs, modern smartphones use a dedicated Neural Processing Unit (NPU) to efficiently run AI and machine learning tasks directly on the device. These specialized hardware accelerators are designed to efficiently handle the demanding mathematical operations inherent in artificial intelligence (AI) and machine learning (ML) workloads, particularly neural network inference.
Real-time photography enhancements are one of the most visible benefits of the NPU in smartphones. Before NPUs, AI tasks on mobile devices were largely relegated to the general-purpose CPU or the graphics-centric GPU. While capable, these components are not architecturally optimized for the repetitive, low-precision tensor calculations that characterize most neural networks. The introduction of NPUs addresses this inefficiency by providing a dedicated, highly parallel, and power-efficient processing block, fundamentally altering how AI is executed on the edge and enabling a new generation of intelligent, responsive applications.
Quick Answer
An NPU (Neural Processing Unit) in smartphones is a specialized processor designed to run AI and machine learning tasks efficiently. It handles neural network processing directly on the device, improving speed, reducing power consumption, and enabling real-time features like image recognition, voice assistants, and smart photography.
Core Concept
This section explores the fundamental design principles and architectural specialization that define an NPU. Grasping these core concepts is vital for understanding why NPUs are uniquely efficient for AI workloads. At its heart, the NPU’s core concept revolves around specialization. Unlike general-purpose CPUs or GPUs, an NPU is purpose-built to accelerate the specific mathematical operations fundamental to neural networks, such as matrix multiplications and convolutions. It achieves this through a highly parallel architecture, often incorporating systolic arrays or vector processing units, which are optimized for fixed-point or low-precision floating-point arithmetic (e.g., INT8, FP16). This architectural choice represents a fundamental system-level tradeoff inherent to edge devices, prioritizing higher throughput and lower power consumption by minimizing silicon area, memory bandwidth, and energy required per operation compared to higher precision alternatives. Consequently, this design prioritizes throughput and energy efficiency for inference tasks—where pre-trained models are used to make predictions or classifications—over the more computationally intensive training phase. The role of NPU in smartphones centers on accelerating neural network inference efficiently within strict mobile power limits.
How It Works

This section describes the practical process by which an NPU executes pre-trained neural network models. Understanding its operational flow reveals how NPUs achieve their speed and efficiency in AI processing. In practice, an NPU functions by ingesting a pre-trained neural network model, typically in an optimized format like TensorFlow Lite or ONNX, and executing its layers sequentially or in parallel. The accompanying software stack, which includes dedicated drivers and AI frameworks, is responsible for compiling and optimizing the model graph to suit the NPU’s specific architecture. Internally, specialized compute engines within the NPU perform these tensor operations, leveraging dedicated on-chip memory (SRAM) for rapid access to model weights and activations. This on-chip memory, often ranging from tens of kilobytes to a few megabytes, is crucial for minimizing latency by keeping frequently accessed data proximate to the compute units, as accessing slower off-chip system RAM can introduce significant delays and consume disproportionately more power. Furthermore, NPUs typically process data using lower precision data types, a design choice that further reduces memory bandwidth requirements and power consumption. To ensure seamless operation, the NPU also integrates control logic and Direct Memory Access (DMA) controllers, facilitating efficient data movement between its internal memory and the main system RAM, thereby minimizing latency and maximizing throughput.
System-Level Explanation
This section explains how the NPU integrates and operates within the larger System-on-Chip (SoC) environment. Understanding this system-level interaction is crucial for appreciating how the NPU optimizes overall device performance and power efficiency. Within a smartphone’s System-on-Chip (SoC), the NPU is a key component of a broader heterogeneous computing environment. It operates in conjunction with the CPU, GPU, and Digital Signal Processor (DSP), with each component handling tasks best suited to its unique architecture. Specifically, the CPU typically manages control flow and less parallelizable tasks, the GPU handles graphics rendering and certain high-precision parallel computations, and the DSP frequently processes audio and sensor data. Within modern SoCs, the NPU in smartphones works alongside CPUs and GPUs to balance AI workloads intelligently.
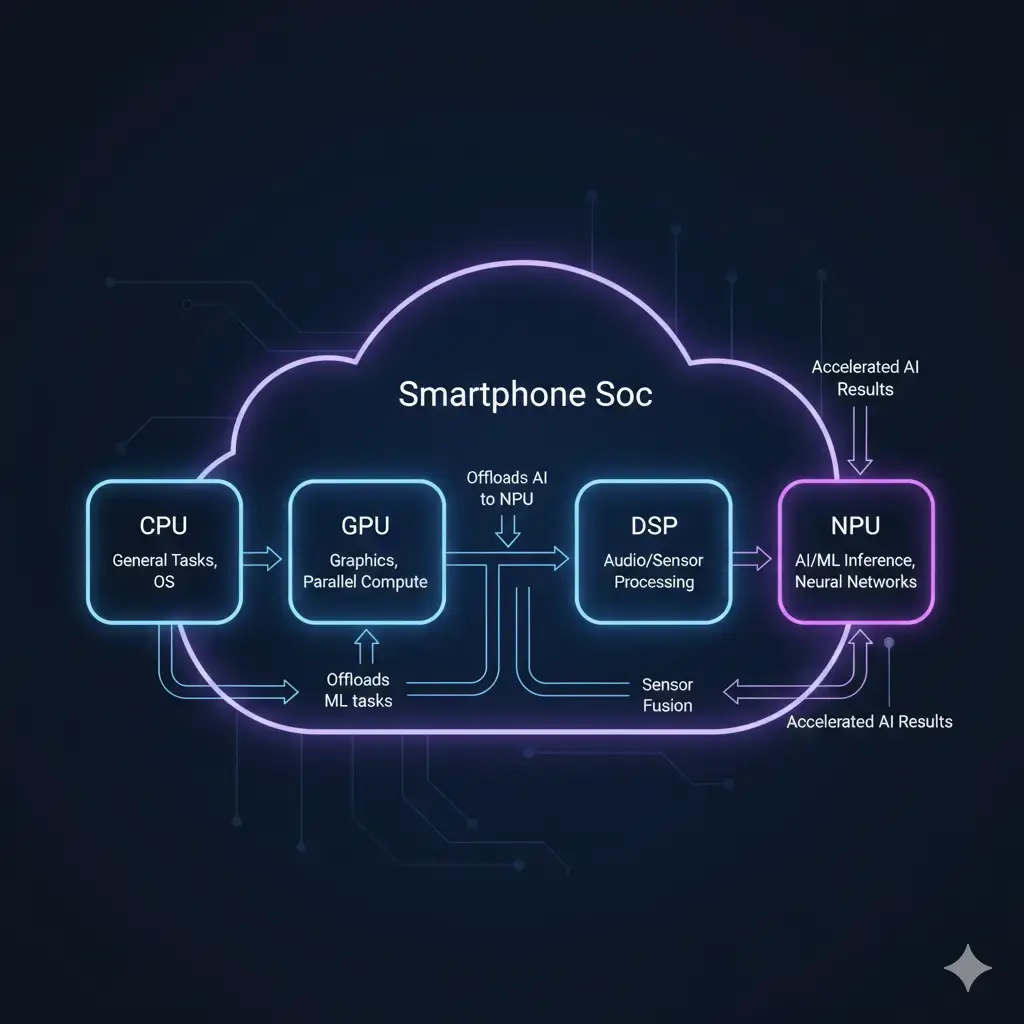
The NPU’s distinct role is to offload AI/ML inference, thereby freeing up the CPU and GPU to focus on their primary functions. This system-level workload distribution ensures that the overall power budget of the mobile SoC, typically constrained to a few watts, is utilized most efficiently, preventing general-purpose cores from becoming thermally throttled or consuming excessive power when executing AI workloads for which they are not optimized. This architectural necessity underscores the fundamental differences in design philosophy between edge and cloud AI processing. Ultimately, this intelligent workload distribution ensures that the most demanding AI tasks are handled by the most efficient hardware. The result is overall system performance improvements, reduced power consumption for AI features, and superior thermal management compared to attempting to run all AI on general-purpose cores.
Engineering Constraints
This section outlines the significant engineering challenges encountered when developing and integrating NPUs into smartphones. Recognizing these constraints is key to understanding the practical limitations and architectural tradeoffs of mobile AI hardware. Designing and integrating an NPU into a smartphone SoC presents significant engineering constraints. Foremost among these are strict power and thermal envelopes. While NPUs are inherently designed for efficiency, sustained heavy AI workloads can still generate considerable heat. This often leads to thermal throttling, where performance can be reduced by 20-50% to prevent overheating. This throttling behavior is a direct consequence of the limited heat dissipation capabilities inherent within a compact smartphone chassis. Thermal and memory limits significantly influence how the NPU in smartphones sustains performance under continuous AI processing.
The NPU’s power budget within an SoC is typically limited to hundreds of milliwatts to a few watts, a stark contrast to cloud-based accelerators that can consume hundreds of watts. These fundamental power and thermal envelopes are architectural realities for mobile devices, not temporary design hurdles. Memory bandwidth and capacity also pose critical limitations. While NPUs rely on fast access to model weights and activations, the shared LPDDR5/5X mobile bandwidth (typically 50-70 GB/s) can easily become a bottleneck for larger models. Similarly, the total system RAM on smartphones, typically 8-16 GB, is a shared resource, further restricting the memory exclusively available for large AI models. Furthermore, on-chip NPU memory is limited, which restricts the size and complexity of models that can run entirely within the NPU’s fastest memory. This frequently necessitates fallback to slower system RAM or even the CPU/GPU for processing parts of the model. This model size versus device capacity constraint means that models exceeding a few megabytes in total parameter size often incur significant latency penalties due to frequent data transfers from main system memory, highlighting a key architectural challenge for deploying large models at the edge.
Key Capabilities
This section details the specific advanced functionalities and benefits that NPUs bring to modern smartphones. Understanding these capabilities reveals the direct impact of NPUs on user experience and the evolution of mobile applications. The NPU’s inherent specialization unlocks several key capabilities for modern smartphones. This includes facilitating real-time, low-latency AI model processing directly on the device. Such on-device capabilities are crucial for applications like instantaneous language translation, voice assistants, and augmented reality (AR), as they can operate without constant reliance on cloud connectivity.
This on-device processing significantly reduces the network latency inherent in cloud communication, which can range from tens to hundreds of milliseconds depending on network conditions, making interactive AI applications feel substantially more responsive. This balance between edge and cloud execution is a continuous engineering consideration, driven by both performance and power efficiency demands. Moreover, by keeping sensitive user data on-device for AI model processing, NPUs can significantly contribute to enhanced privacy and reduce certain security exposures, although they do not eliminate all risks. Their high energy efficiency for ML tasks also enables sustained AI-powered features, such as advanced computational photography (e.g., portrait mode, object recognition, super-resolution) and on-device learning for personalization. This is achieved while optimizing battery usage compared to general-purpose processors.
Design Tradeoffs
This section explores the fundamental compromises inherent in NPU design, particularly concerning specialization, flexibility, and precision. Recognizing these tradeoffs is essential for understanding the strengths and limitations of current NPU architectures. NPU design invariably involves inherent tradeoffs, chiefly concerning specialization, flexibility, and precision. While highly optimized for common neural network operations and lower precision data types (INT8, FP16), this very specialization implies that NPUs are often inefficient or even incapable of general-purpose computing or handling entirely novel AI paradigms.
The specialized architecture of the NPU in smartphones improves efficiency but limits flexibility for non-AI tasks. This system tradeoff between fixed-function efficiency and general-purpose programmability is a core design decision for edge AI accelerators, directly impacting their adaptability to future AI model architectures. Consequently, the reliance on quantization (e.g., INT8) for efficiency can lead to minor accuracy degradation, necessitating careful calibration or quantization-aware training. Moreover, the fixed architectural constraints mean that achieving future performance gains within existing power and thermal envelopes is increasingly challenging. Supporting higher precision (FP32) for highly sensitive models, for instance, often comes at a high cost in both performance and power.
Real-World Usage
This section showcases practical examples of how NPUs are currently employed across various smartphone applications and features. Understanding these real-world uses demonstrates the tangible benefits and ongoing challenges of NPU integration. In practical terms, NPUs power a wide array of smartphone functionalities across various applications. Computational photography, for instance, heavily leverages NPUs for tasks such as semantic segmentation in portrait mode, real-time object detection, noise reduction, and HDR processing. Natural Language Processing (NLP) also significantly benefits from NPU acceleration, enabling on-device speech recognition, text prediction, and translation, which in turn facilitates offline capabilities. Even biometric authentication, including facial recognition and fingerprint matching, relies on NPUs for rapid and secure processing.
Many AI camera features today depend directly on the NPU in smartphones rather than cloud processing. However, challenges in NPU utilization do persist. Sometimes, applications fail to properly utilize the NPU due to SDK limitations or suboptimal optimization, often leading to inefficient CPU/GPU fallback. Additionally, developers frequently face difficulty in porting and optimizing existing AI models to suit the diverse NPU architectures available. The sheer size of some state-of-the-art AI models can exceed the practical memory capacity or bandwidth available on mobile devices, even with NPU acceleration, often necessitating model compression or architectural changes for efficient edge deployment. This constraint fundamentally shapes the design and optimization strategies for on-device AI. For a comprehensive comparison of how on-device AI (including NPUs) stacks up against traditional cloud computation, see On-Device AI vs Cloud AI: What Really Powers Your Gadgets in 2026?.
Industry Direction
This section outlines the current trajectory and future developments within the NPU industry and its supporting software ecosystem. Understanding these directions provides insight into the ongoing evolution and increasing sophistication of mobile AI. Looking ahead, the industry is clearly moving towards more sophisticated NPU architectures and a more robust software ecosystem. Key efforts are focused on improving developer SDKs and APIs (e.g., Android NNAPI, Apple Core ML, Qualcomm AI Engine Direct SDK) to reduce fragmentation and streamline model deployment. There’s also a strong emphasis on developing highly optimized compilers and runtime libraries capable of translating various ML frameworks into NPU-executable code, thereby maximizing hardware utilization.
The concept of heterogeneous computing is continually being refined, with advanced schedulers now managing and distributing AI tasks across the CPU, GPU, DSP, and NPU based on real-time workload characteristics. Future directions include exploring even lower precision data types (e.g., INT4) and developing more flexible architectures that can adapt to evolving AI models while steadfastly maintaining power efficiency. Future improvements in the NPU in smartphones focus on better efficiency per watt and support for larger models. Future improvements in the NPU in smartphones focus on better efficiency per watt and support for larger models.
Technical Context
Benchmark comparisons often highlight how the NPU in smartphones delivers higher AI performance per watt than general-purpose cores. NPU in smartphones plays an important role in understanding these system limits. This section provides specific performance metrics and technical specifications for smartphone NPUs. These quantitative details are crucial for understanding the actual capabilities and limitations of mobile AI hardware in comparison to other platforms. From a technical standpoint, smartphone NPUs typically deliver peak performance ranging from 10 to 45 TOPS (Tera Operations Per Second) for INT8 operations. TOPS quantifies the NPU’s ability to perform trillions of 8-bit integer operations per second, indicating its raw processing power for low-precision AI tasks. However, their sustained throughput under mobile thermal limits often falls into the 15-20 TOPS range, typically consuming less than 1W. This distinction between peak and sustained performance is crucial for understanding real-world user experience, as short bursts of high performance are frequently followed by thermal throttling. For instance, some imaging-focused NPUs can report 18 TOPS at 11.6 TOPS/W.
Benchmark comparisons often highlight how the NPU in smartphones delivers higher AI performance per watt than general-purpose cores. This contrasts sharply with cloud GPUs, which boast hundreds of GB of VRAM and operate within significantly higher power envelopes. Cloud GPUs often operate with power budgets of 200-700W and provide memory bandwidths of hundreds of GB/s to over a TB/s, enabling them to handle much larger and more complex models with higher precision. In comparison, mobile SoC power budgets are exceptionally tight, with a full SoC typically operating within a 6-8W total envelope. While LPDDR5/5X provides 50-70 GB/s bandwidth, it’s important to remember this is shared system memory, not dedicated VRAM, a fundamental architectural difference from cloud accelerators that impacts sustained AI performance. To compare the performance of mobile NPUs across devices and use cases, engineers frequently reference the MLPerf Mobile benchmark as an industry standard. Benchmarks such as MLPerf Mobile have consistently shown generation-to-generation improvements of up to 3x throughput and 12x latency reduction, clearly demonstrating the rapid advancement in NPU capabilities.
Key Takeaways
This section summarizes the most critical insights and conclusions regarding NPUs in smartphones. These key takeaways consolidate understanding of their importance, capabilities, and inherent design challenges. In essence, NPUs are specialized, power-efficient hardware accelerators critical for enabling sophisticated on-device AI in smartphones, specifically by offloading neural network inference from general-purpose processors. Their architecture is finely optimized for parallel, low-precision tensor operations, which in turn facilitates the real-time, private, and efficient execution of AI features such as advanced photography and voice assistants. However, their design inherently involves engineering tradeoffs related to thermal management, memory constraints, and the delicate balance between specialization and flexibility. The ongoing evolution of NPU hardware and its accompanying software ecosystems is actively striving to overcome these challenges, pushing towards even greater integration of sophisticated AI capabilities directly into our mobile devices.
Evidence & Methodology
This section details the sources and analytical methods used to compile the information presented in this article. Understanding the methodology is crucial for assessing the credibility and robustness of the insights provided. These insights are drawn from a comprehensive analysis of public technical specifications from leading SoC manufacturers (e.g., Apple, Qualcomm, Google), established industry benchmarks such as MLPerf Mobile, and pertinent academic research into neural network acceleration and quantization techniques. Specific performance figures, including TOPS, power consumption ranges, and memory bandwidth, are derived from published product data sheets and independent hardware reviews. Discussions on engineering constraints and design tradeoffs reflect common challenges encountered in semiconductor design and system integration, consistent with observations from the development of mobile computing platforms.
FAQs
This section addresses frequently asked questions about Neural Processing Units in smartphones. These answers clarify common queries and deepen understanding of NPU functionality and limitations.
What is the primary benefit of an NPU over a CPU or GPU for AI tasks?
The primary benefit is significantly higher energy efficiency and enhanced throughput, specifically for neural network inference. NPUs are architecturally optimized for the repetitive, low-precision matrix operations fundamental to AI, enabling them to perform these tasks with considerably less power and greater speed than general-purpose CPUs or graphics-focused GPUs. This specialization is a critical system-level tradeoff for edge devices, where power consumption and thermal management are paramount hardware constraints.
Can NPUs be used for training AI models on a smartphone?
While some limited on-device learning or fine-tuning is indeed possible, NPUs are primarily designed and optimized for inference—that is, executing pre-trained models. Large-scale AI model training, however, typically demands much higher computational power, memory capacity, and precision (FP32)—characteristics more akin to cloud-based GPUs or specialized AI accelerators, which are not present in mobile NPUs. The model sizes and computational intensity for training often exceed the hardware limits of mobile devices, making cloud environments the practical choice for most training workloads
How do developers utilize the NPU in their applications?
Developers typically leverage high-level AI frameworks such as TensorFlow Lite or PyTorch Mobile, both of which offer backend support for NPU acceleration. They also interact with platform-specific APIs, including Android NNAPI (Neural Networks API) or Apple Core ML. These APIs abstract away the underlying NPU hardware details, allowing models to be compiled and executed efficiently on the available NPU.