Table of Contents
NPU Architectures for Real-Time 8K Upscaling in 2026 Smart TV SoCs
2026 Smart TV NPU Benchmarks measure real-time 8K AI upscaling performance in modern Smart TV SoCs, evaluating sustained throughput, latency, memory bandwidth efficiency, and thermal stability under continuous playback conditions.
Modern 8K AI upscaling relies on executing large super-resolution (SR) models in real time, often requiring sustained performance in the range of tens to well over one hundred INT8 TOPS. These workloads are dominated by convolution and matrix-multiplication operations, and NPU architectures are specifically optimized around those patterns. The ability of a Smart TV SoC to maintain stable NPU performance directly impacts visual quality, frame-rate consistency, and responsiveness during 8K playback.
Unlike mobile devices that handle short inference bursts, Smart TVs must sustain AI inference for hours within a fanless enclosure. As a result, NPU design is fundamentally shaped by power efficiency, memory bandwidth, and thermal stability rather than peak benchmark numbers alone.
At a Glance
- 2026 Smart TV NPU benchmarks focus on sustained on-device performance for real-time 8K upscaling at 60–120Hz.
- Memory bandwidth efficiency and thermal stability matter more than peak TOPS.
- Modern Smart TV NPUs rely on systolic MAC arrays, INT8/INT4 inference, and large on-chip SRAM.
- Tile-based execution keeps latency low while reducing external DRAM traffic.
- On-device processing is essential; cloud-based 8K upscaling is impractical.
What Are 2026 Smart TV NPU Benchmarks?
2026 Smart TV NPU benchmarks measure a system-on-chip’s ability to perform real-time 8K AI upscaling at 60–120Hz while remaining within strict power, thermal, and memory bandwidth limits. These benchmarks emphasize sustained throughput rather than peak TOPS.
Key benchmark dimensions include:
- Sustained INT8/INT4 throughput under continuous load
- End-to-end upscaling latency (typically targeting under 15 ms)
- Memory subsystem efficiency and data reuse
- Thermal stability over long viewing sessions
Unlike synthetic AI benchmarks, Smart TV NPU benchmarks reflect real video pipelines where inference overlaps with decoding, HDR processing, motion compensation, and display scan-out.
Why 8K AI Upscaling Is Computationally Demanding
Real-time 8K AI upscaling is computationally extreme due to both data volume and model complexity. Upscaling from 4K to 8K increases pixel count fourfold, requiring inference across more than 33 million pixels per frame.
Unlike traditional interpolation, AI upscaling uses deep convolutional or hybrid CNN-transformer models used in deep learning super-resolution models to infer missing high-frequency details. These models typically contain tens to hundreds of millions of parameters and execute billions of operations per frame. Even with INT8 quantization, memory requirements for weights and activations can reach 50–200 MB.
Maintaining this level of inference at 60Hz or 120Hz pushes the limits of on-chip compute density, memory bandwidth, and thermal dissipation. For this reason, real-time 8K upscaling is fundamentally a hardware-constrained problem rather than a software-only challenge.
How AI Upscaling Pipelines Run on Smart TVs
In 2026, Smart TVs, AI upscaling is deeply integrated into the SoC video pipeline. The process begins with hardware video decoders that handle compressed input streams. Decoded frames are passed directly into the NPU for super-resolution inference.
To control latency and memory traffic, NPUs process frames using tile-based or line-buffered execution rather than full-frame buffering. This allows inference to overlap with display scan-out and downstream video processing. End-to-end latency typically remains under 10–20 milliseconds, which is essential for smooth playback and low input lag.
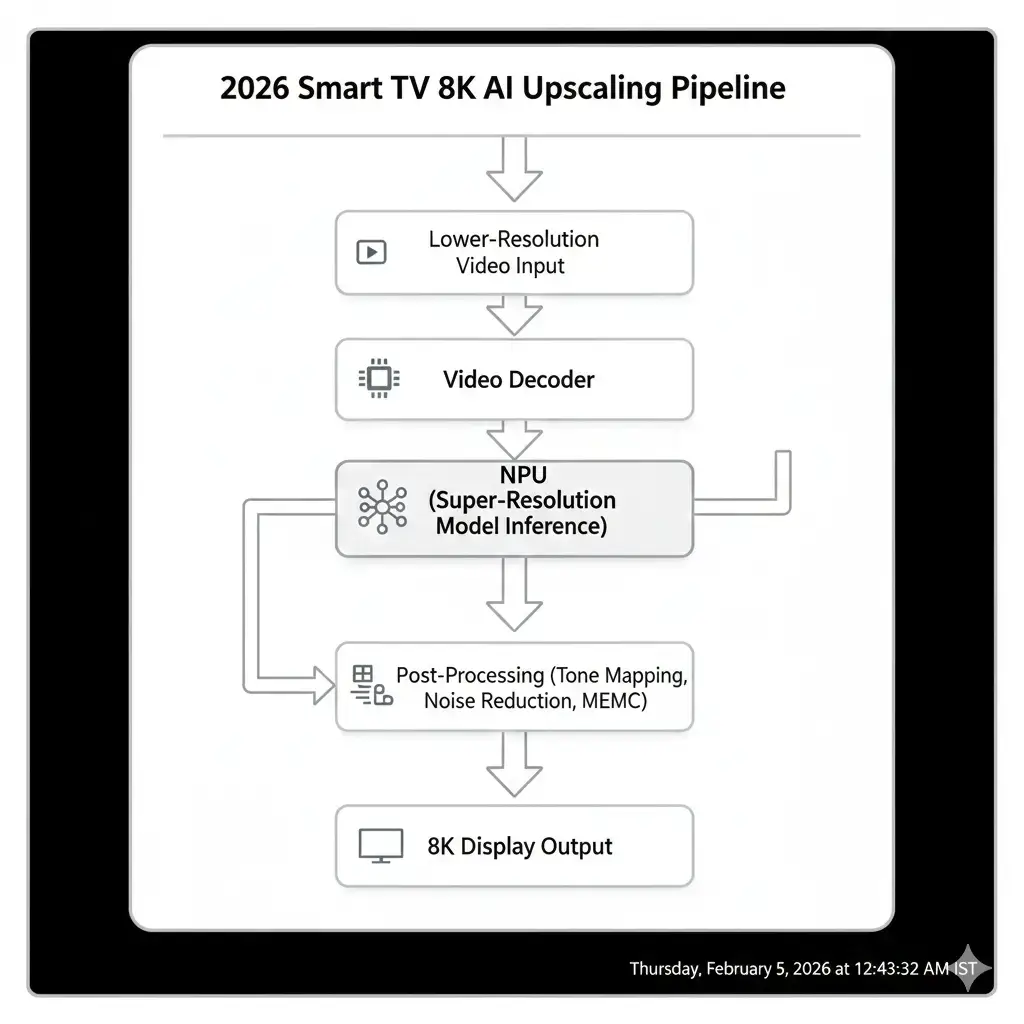
After NPU inference, frames pass through fixed-function video blocks for tone mapping, noise reduction, and motion estimation or compensation. The final 8K output is then delivered to the display engine at 60Hz or 120Hz. This tightly coupled pipeline reflects a system-level tradeoff between throughput, latency, and power efficiency.
Inside the NPU: Smart TV NPU Architecture for Video AI
NPUs in 2026 Smart TV SoCs are purpose-built for video inference workloads, similar in principle to on-device AI accelerators in smartphones. Most designs center on highly parallel MAC arrays organized as systolic or semi-systolic structures, commonly ranging from 64×64 to 128×128 processing elements.
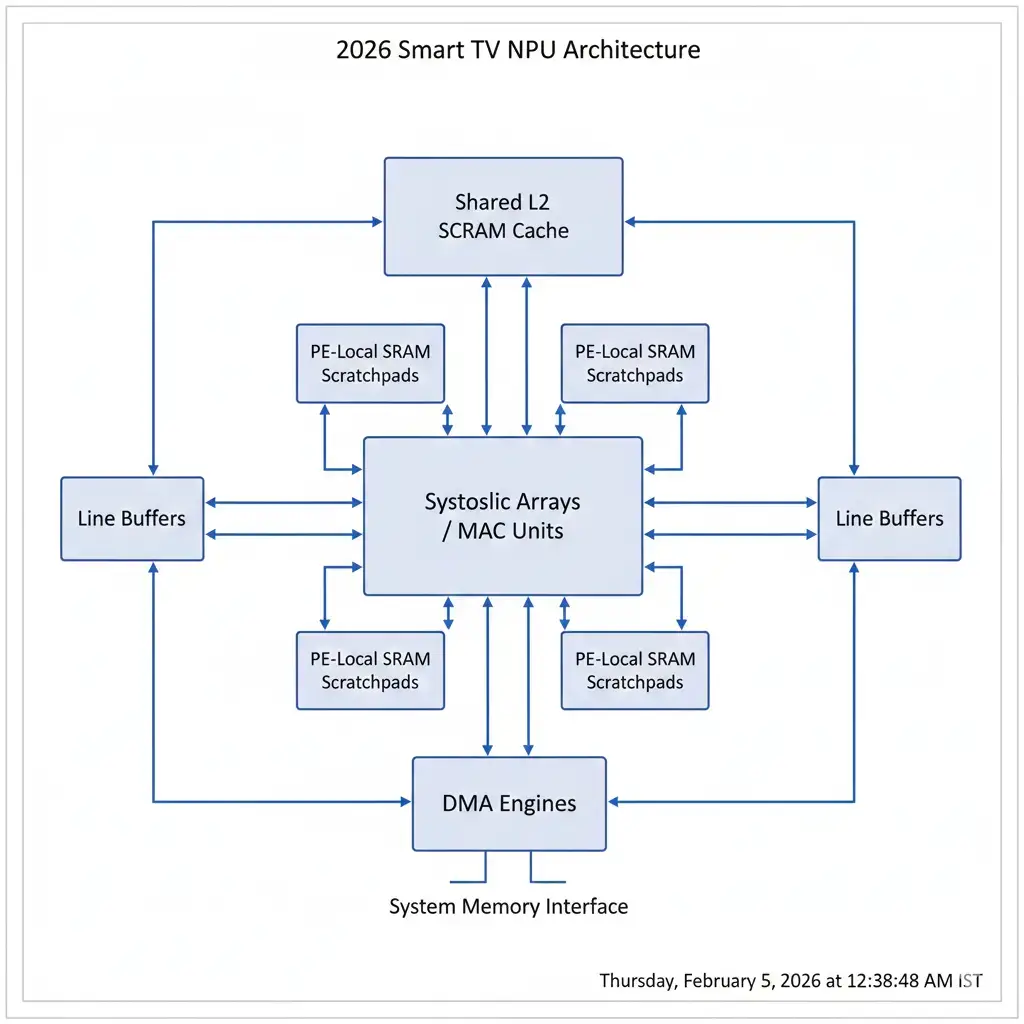
These architectures excel at dense matrix multiplications and convolutions, achieving high utilization on super-resolution workloads. INT8 inference is the primary execution mode, with some support for INT4 or mixed precision in selected layers to improve efficiency without visible quality loss.
On-chip memory hierarchies are critical to performance. Typical designs include:
- Processing-element local SRAM for fast reuse
- Shared L2 SRAM measured in multiple megabytes
- Dedicated line buffers for tiled video processing
Keeping data on-chip dramatically reduces reliance on external memory, which is both slower and more power-hungry. High-throughput DMA engines manage data movement between SRAM and external LPDDR5X or LPDDR6 memory, enabling sustained bandwidth in the 64–128 GB/s range.
Memory Bandwidth and Data Movement Challenges
Real-time 8K upscaling places extreme pressure on memory subsystems due to memory bandwidth limitations in modern SoCs. At 120Hz, effective bandwidth requirements approach or exceed 100 GB/s when accounting for intermediate feature maps and model weights.
External memory bandwidth alone is insufficient. Efficient reuse of on-chip SRAM is essential to avoid repeated DRAM accesses, which consume an order of magnitude more energy per bit. Poorly optimized tiling strategies can multiply effective bandwidth demand by several times, quickly becoming a bottleneck.
Another major challenge is contention on the SoC’s internal interconnect. The NPU, GPU, and video processing blocks often access shared memory concurrently. Without careful arbitration, this contention can introduce latency spikes or frame instability, underscoring the importance of system-level memory scheduling.
Sustained AI Workloads and System Constraints
Unlike burst-oriented AI tasks, video upscaling requires continuous inference for hours at a time. Sustained workloads drive SoCs toward their thermal limits, commonly in the 80–95°C range, at which point clock throttling becomes unavoidable.
While peak NPU performance figures may exceed 200 TOPS, sustained throughput is typically much lower. Maintaining 50–150 TOPS over long sessions without throttling is the real engineering challenge. This makes sustained benchmarks far more meaningful than peak specifications.
Bandwidth pressure, thermal buildup, and power limits interact continuously. Even small inefficiencies in data movement or compute utilization can lead to dropped frames, micro-stutter, or quality fallback during prolonged playback.
Power and Thermal Limits in TV SoCs
Smart TV SoCs operate within total power budgets of roughly 20–50W due to fanless industrial design. Under sustained 8K workloads, NPUs alone may consume 5–15W.
Sustained HDR playback further increases thermal load, often triggering dynamic clock reductions of 10–25%, a behavior also seen in thermal throttling during sustained AI workloads on other consumer devices. These reductions directly affect inference throughput and can force simpler upscaling models or lower frame rates.
Advanced power-management techniques such as fine-grained clock gating, power gating, and dynamic voltage and frequency scaling are essential to balancing performance with thermal stability. Effective thermal design is as critical as raw compute capability in determining real-world upscaling quality.
On-Device Inference Benchmarks and Trade-Offs
On-device inference benchmarks for 2026 Smart TV NPUs prioritize sustained performance metrics:
- Real 8K upscaling FPS
- End-to-end pipeline latency
- Power consumption under continuous load
Aggressive quantization improves efficiency but can introduce cumulative error across multi-stage pipelines if not paired with quantization-aware training. The tradeoff between model complexity, image quality, and sustained performance is central to Smart TV NPU design.
Public, frame-accurate benchmark data remains limited. However, proxy data from edge and mobile NPUs suggests that 8K-class inference at 30–60 fps consumes several watts, with high-end TV SoCs allocating more power to achieve 120Hz operation.
Why Upscaling Must Run at the Edge
Cloud-based 8K upscaling is impractical. Network latency alone would exceed acceptable limits, while bandwidth requirements for uncompressed 8K video are orders of magnitude beyond residential internet capabilities.
On-device processing eliminates latency, preserves privacy, and ensures consistent quality, highlighting the broader on-device AI vs cloud AI tradeoffs shaping modern consumer electronics. For real-time video workloads, edge inference is not a preference but a necessity.
Future Directions for Smart TV NPU Design
Future Smart TV NPUs will emphasize higher compute density, larger on-chip memory, and better software tooling. INT8 and INT4 throughput will continue to rise as process nodes advance, while SRAM capacity may expand to reduce DRAM dependence.
Architectures will increasingly support more complex models, including temporally aware and transformer-based upscaling networks. Compiler-driven operator fusion and improved SDKs will be critical to translating theoretical performance into real-world gains.
Key Takeaways
- 2026 Smart TV NPUs are essential for real-time 8K AI upscaling, typically sustaining 50–150+ INT8 TOPS
- Architecture favors systolic MAC arrays, INT8/INT4 execution, and large on-chip SRAM hierarchies
- Memory bandwidth near 100 GB/s is required, making data reuse and tiling critical
- Power and thermal limits constrain sustained performance more than peak TOPS
- On-device inference is mandatory for low latency, bandwidth efficiency, and privacy
- Future designs will focus on memory integration, sustained efficiency, and software maturity
Frequently Asked Questions
What are the 2026 Smart TV NPU benchmarks?
They measure sustained AI upscaling performance, latency, power efficiency, and thermal stability during real-time 8K playback.
How many TOPS are needed for real-time 8K upscaling?
Typically 50–150 INT8 TOPS sustained, depending on model complexity and frame rate.
Why not use cloud AI for upscaling?
Latency, bandwidth, cost, and privacy constraints make cloud-based 8K upscaling impractical.
Do higher TOPS always mean better image quality?
No. Memory efficiency, sustained clocks, and model design matter more than peak TOPS.
Why does AI upscaling throttle over time?
Fanless TV designs hit thermal limits during sustained workloads, forcing clock reductions.