Table of Contents
Sustained AI Performance vs Peak TOPS describes the critical difference between an AI accelerator’s theoretical maximum compute capability and the real-world throughput it can deliver over time. Peak TOPS represents the theoretical maximum arithmetic throughput of an AI accelerator under ideal, often unattainable, conditions. Sustained AI performance, conversely, is the actual achievable throughput over extended periods, dictated by real-world constraints such as memory bandwidth, power and thermal limits, software overhead, and workload characteristics. The significant disparity between these two metrics is a fundamental engineering challenge, where system-level bottlenecks often overshadow raw compute capability, directly impacting a device’s ability to deliver consistent performance for complex AI tasks.
In the realm of AI hardware, the pursuit of ever-higher computational throughput is relentless. Manufacturers frequently highlight “Peak TOPS” (Tera Operations Per Second) as a primary metric for their accelerators. However, experienced engineers recognize that this figure rarely translates directly to real-world application performance. The gap between theoretical peak and observed sustained AI performance is a critical area of analysis, revealing deep insights into compute architecture, system design, and the inherent characteristics of AI workloads. In practice, real-world AI accelerator throughput is often significantly lower than theoretical peak performance due to architectural bottlenecks and system-level constraints. This article dissects this disparity from an engineering perspective, focusing on the underlying silicon-level reasoning and architectural tradeoffs.
Understanding Peak TOPS and Sustained AI Performance
Understanding Sustained AI Performance vs Peak TOPS is essential when evaluating AI accelerator benchmarks because real-world throughput rarely matches theoretical compute claims.
Peak TOPS (Theoretical Maximum Operations Per Second): Peak TOPS quantifies the maximum number of arithmetic operations an accelerator can perform per second, assuming perfect conditions. This figure is derived from the aggregate count of specialized compute units (e.g., Tensor Cores, XMX units, Neural Engines), their clock frequency, and the number of operations they can execute per cycle for a specific data type (e.g., FP16, BF16, INT8). It represents the raw, unconstrained potential of the arithmetic fabric, often serving as an internal engineering target to push transistor density and clock speed limits, which can be a key differentiator in initial product marketing.
Sustained AI Performance (Real-World Achievable Throughput): Sustained AI performance measures the actual, consistent throughput an accelerator can maintain over an extended period when executing real-world AI workloads. This metric inherently accounts for all system-level bottlenecks and operational realities, including:
- Memory Bandwidth and Latency: The rate at which data can be moved to and from compute units.
- Power and Thermal Limits: Dynamic voltage and frequency scaling (DVFS) and thermal throttling mechanisms that reduce clock speeds to stay within a defined thermal design power (TDP) envelope, directly impacting sustained performance over time.
- Software Stack Overheads: Latency and CPU cycles consumed by drivers, compilers, AI frameworks, and operating system scheduling.
- Workload Characteristics: Factors like batch size, data locality, sparsity, and the specific mix of operations in a neural network.
Why Peak TOPS and Sustained AI Performance Diverge
These memory bandwidth bottlenecks prevent compute units from operating at full capacity, creating a major gap between peak TOPS and sustained AI performance. The divergence between peak and sustained performance arises from the interplay of several architectural and operational factors:
- Compute vs. Data Movement Imbalance: Modern AI accelerators are designed with an immense number of arithmetic units. However, these units are often starved for data. The rate at which data can be fetched from off-chip memory (the “memory wall”) is significantly slower than the rate at which compute units can process it. This means compute units spend a considerable amount of time idle, waiting for operands, directly impacting latency behavior for real-time inference tasks.
- Memory Hierarchy Effectiveness: Elaborate memory hierarchies (L1/L2 caches, High-Bandwidth Memory – HBM) are engineered to mitigate the memory wall. On-chip caches provide low-latency access to frequently used data, while HBM offers significantly higher aggregate bandwidth than traditional GDDR/DDR. However, even HBM has its limits in terms of capacity, latency, and the energy cost of data movement, becoming the primary bottleneck for many large AI models subject to thermal and power constraints, thus limiting sustained performance for complex offline execution.

- Power and Thermal Management: Achieving peak TOPS often requires operating compute units at their maximum voltage and frequency, which generates substantial heat and consumes significant power. Under sustained load, devices will dynamically reduce clock speeds (throttling) to stay within their thermal design power (TDP) envelope and prevent overheating. This directly reduces the effective operations per second, impacting thermal stability and overall sustained performance.
- Software Stack Overhead: The complex software stack required to translate high-level AI models into low-level hardware instructions introduces a performance “tax.” Kernel launches, memory management, data transfers, and framework-specific operations consume CPU cycles and introduce latency, particularly for small batch sizes or latency-sensitive inference, where these overheads cannot be amortized over a large amount of computation, leading to unpredictable latency behavior.
- Specialized Unit Utilization: While specialized units (e.g., Tensor Cores) offer extreme efficiency for specific operations (like matrix multiplication), their utilization depends on the workload mapping perfectly to their capabilities. Workloads with irregular access patterns, non-standard data types, or complex control flow may fall back to less efficient general-purpose cores or leave specialized units underutilized, leading to a lower sustained performance for diverse or non-standard AI tasks.
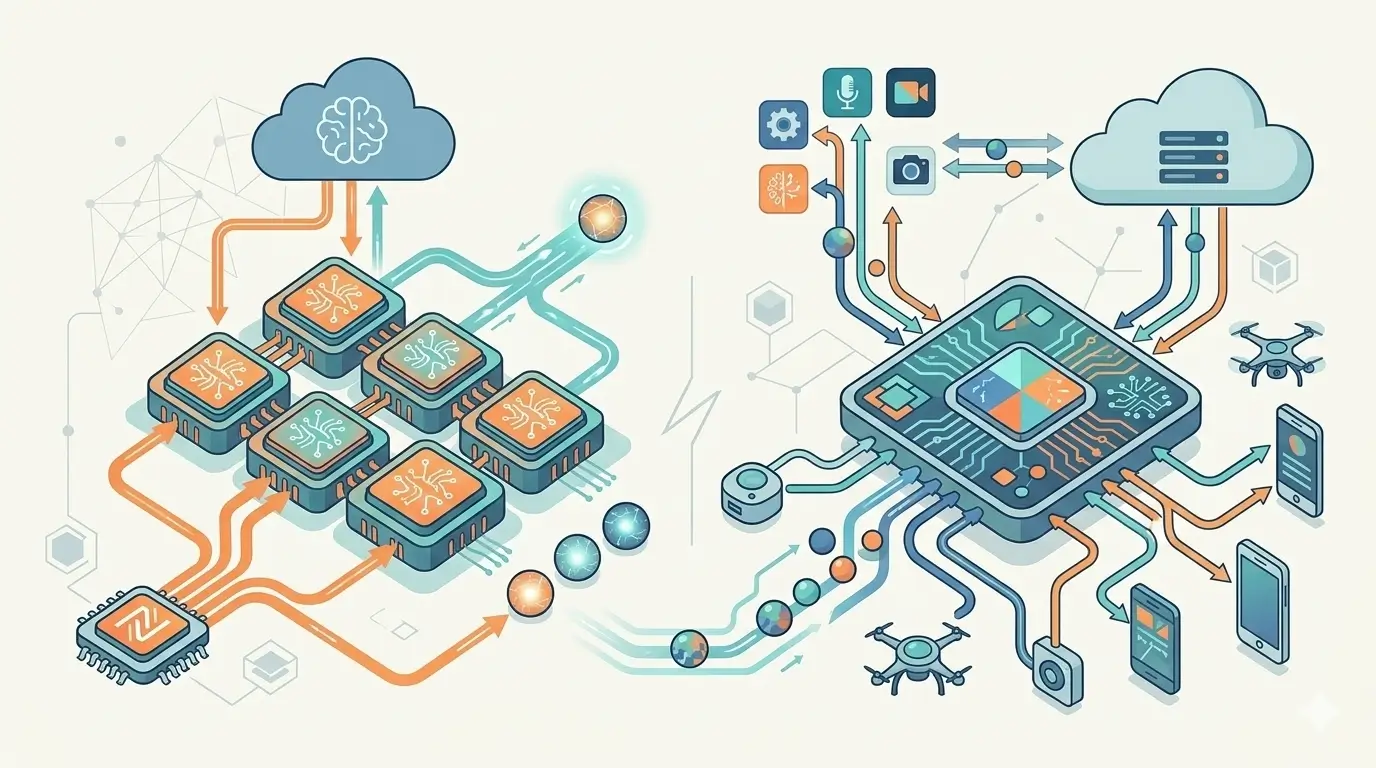
AI Accelerator Architecture Behind Peak and Sustained Performance
AI accelerator architectures are a complex interplay of specialized compute, memory subsystems, and interconnects, each designed with specific tradeoffs that impact both peak and sustained performance. The fundamental challenge of Sustained AI Performance vs Peak TOPS drives many of these design decisions.
- Specialized Compute Units: Dedicated hardware blocks (e.g., NVIDIA Tensor Cores, AMD XMX engines, Apple Neural Engine) are optimized for the dominant AI operations (matrix multiplication, convolution) and for specific low-precision data types (FP16, BF16, INT8). They offer significantly higher TOPS/W and TOPS/area compared to general-purpose FP32/FP64 units, enabling high peak throughput for targeted workloads. However, their specialization limits flexibility for novel or non-standard operations, potentially reducing sustained performance for evolving AI models.
- High-Bandwidth Memory (HBM): HBM stacks (e.g., HBM3e) are integrated directly onto the accelerator package via an interposer. They provide massive aggregate memory bandwidth (e.g., terabytes/second), crucial for feeding the hungry compute units. While essential for high sustained performance in memory-bound workloads, HBM is expensive, adds packaging complexity, and still poses a latency challenge relative to on-chip caches, thereby impacting sustained performance for very large models.
- Unified Memory Architecture (UMA): Architectures like Apple’s M-series integrate CPU, GPU, and Neural Engine onto a single die with a unified memory pool (LPDDR5/X). This can help reduce data copies between components, significantly reducing latency and power consumption for data movement. While its absolute peak bandwidth might be lower than HBM-equipped discrete accelerators, its efficiency and low latency for data movement across the integrated components contribute to very stable and predictable sustained performance, positively impacting battery impact in mobile devices.
- High-Speed Interconnects: Proprietary interconnects (e.g., NVIDIA NVLink, AMD Infinity Fabric) and open standards (e.g., UCIe) are designed for low-latency, high-bandwidth communication between multiple accelerators or nodes. These are critical for scaling AI workloads that exceed the capacity of a single chip, but communication overheads can still limit sustained performance in distributed training environments.
- Power Delivery and Cooling: The design of the power delivery network (PDN) and the thermal solution directly dictate the maximum sustained power an accelerator can draw and the heat it can dissipate. These physical limits are often the ultimate arbiters of sustained clock frequencies and, consequently, sustained performance and thermal stability.
Peak vs Sustained Performance Across AI Hardware
The disparity between peak and sustained performance manifests differently across various AI accelerator categories due to their distinct architectural tradeoffs and target applications.
| Characteristic | Data Center (e.g., H100/MI300X) | Integrated (e.g., Apple M-series) | Consumer GPU (e.g., RTX 4090) | Edge AI (e.g., Qualcomm NPU) |
|---|---|---|---|---|
| Peak TOPS (FP16/INT8) | Extremely High | Moderate | High | Low |
| Memory Architecture | Very High Bandwidth HBM | Unified LPDDR5/X (UMA) | High Bandwidth GDDR6X | Low Bandwidth LPDDR4/5 |
| Sustained Performance | Often memory-bound, throttles under load | Latency-optimized, stable, power-efficient | Aggressively throttled under sustained AI | Power-constrained, near peak (INT8) |
| Peak/Sustained Ratio | High divergence (compute often starved) | Moderate divergence (efficient data path) | Very High divergence (thermal/power limited) | Low divergence (designed for efficiency) |
| Primary Bottleneck | Memory bandwidth, thermal limits | Absolute memory bandwidth, model size | Thermal, power, memory bandwidth | Power budget, memory capacity |
| Power Efficiency (TOPS/W) | Good (for specialized ops), high absolute power | Excellent (system-level integration) | Moderate (optimized for bursty graphics) | Excellent (strict power envelopes) |
Analysis of Device Implications:
- Data Center Accelerators (e.g., NVIDIA H100, AMD MI300X): These are “bandwidth beasts” designed with immense HBM capacity and bandwidth to feed their vast compute capabilities. For most real-world large language model (LLM) workloads, which are often memory-bound, sustained performance is dictated by effective HBM bandwidth and data locality, rather than peak FP8/FP16 TOPS. Furthermore, their high TDP necessitates aggressive throttling under sustained load to remain within thermal envelopes, meaning peak clock speeds are rarely maintained in production.
- Integrated Architectures (e.g., Apple M-series): The unified memory architecture provides excellent latency and power efficiency for data movement between CPU, GPU, and Neural Engine, leading to very stable sustained performance. However, the use of LPDDR5(X) results in lower absolute peak memory bandwidth compared to HBM-equipped discrete accelerators. This implies that for very large models or highly memory-bound tasks, the M-series will hit a memory bandwidth ceiling sooner, even if its Neural Engine is highly utilized.
- Consumer GPUs (e.g., RTX 4090): Optimized for bursty gaming workloads, these GPUs offer good GDDR6X memory bandwidth but not HBM-class. For AI, they can achieve impressive burst TOPS, but their thermal and power limits (TDP) are often much lower relative to their peak compute. This leads to severe and rapid throttling under sustained AI workloads, where sustained performance is significantly lower than the theoretical peak, often limited by memory bandwidth and aggressive thermal management.
- Edge AI Devices (e.g., Qualcomm NPU): These devices prioritize power efficiency (TOPS/W) and low latency within extremely strict power budgets, often operating in the few-watt sustained range. Their peak TOPS are significantly lower, but their sustained performance is much closer to their peak due to tight power budgets and efficient thermal management. They are designed for specific, often quantized, inference tasks, and their performance is highly sensitive to model size and data type due to limited memory and compute resources.
Real-World AI Workloads and Sustained Performance
Real-world AI accelerator performance is often evaluated using industry benchmarks such as MLPerf inference benchmarks, which measure sustained throughput across standardized workloads rather than relying on theoretical peak compute metrics.. The distinction between peak and sustained performance has profound implications across various AI applications:
- Large Language Model (LLM) Training: This is typically a compute- and memory-intensive workload. Sustained performance is critical, as training runs for days or weeks. The “memory-bound plateau” is a common state, where performance is limited by the ability to feed data to the compute units. In distributed training, interconnect saturation becomes a major bottleneck, limiting the scalability of sustained performance.
- High-Throughput Inference (Large Batch): For applications like data center inference serving many users, larger batch sizes can amortize memory access latency and software overheads, allowing the accelerator to achieve higher sustained utilization closer to its theoretical potential (though still memory-bound).
- Low-Latency Inference (Small Batch): Real-time applications (e.g., autonomous driving, real-time speech recognition) demand minimal latency per inference. Here, software stack overheads, memory latency, and control flow complexity dominate execution time. Sustained performance relative to peak is often very low, as the system cannot fully utilize its arithmetic units.
- Edge AI Inference: Devices on the edge (e.g., smartphones, IoT) operate under strict power and thermal constraints. Sustained performance is paramount for a consistent user experience. These devices are often designed for high TOPS/W efficiency, with peak and sustained performance being much closer due to conservative power budgets and highly optimized, often quantized, models.
Engineering Limits Behind the Peak vs Sustained Gap
Accelerators must operate within a fixed thermal design power (TDP) limit, forcing clock frequency reductions during sustained workloads. The engineering challenges contributing to the peak vs. sustained performance gap are fundamental and persistent:
- The Persistent Memory Wall: Despite advancements in HBM (HBM3e, HBM4), the fundamental gap between compute capability and memory bandwidth will likely persist and widen. As AI models grow exponentially, feeding massive compute arrays at sufficient rates remains the primary bottleneck. Physical limits of memory stacking, interposer technology, and the energy cost of data movement will continue to drive reliance on techniques like quantization and sparsity.
- Power Density and Cooling Limits: As transistor density increases, the power density of AI accelerators rises. This exacerbates thermal throttling. Future designs will face increasing challenges in dissipating heat, potentially requiring exotic cooling solutions (liquid cooling, immersion cooling) or forcing designers to prioritize power efficiency over raw peak performance, leading to a plateau in clock frequency gains.
- Software Complexity and Optimization Fatigue: The increasing complexity of AI models and heterogeneous hardware architectures places an ever-growing burden on the software stack (compilers, frameworks, drivers). Achieving optimal sustained performance requires continuous, deep optimization, which is resource-intensive and can become a limiting factor in itself.
- Algorithmic Mismatch: The efficiency gains from specialized compute units come at the cost of flexibility. Novel neural network architectures, highly sparse operations without dedicated hardware, or non-standard data types can lead to significant underutilization of specialized hardware, forcing a fallback to less efficient general-purpose cores and reducing sustained performance.
Why Sustained AI Performance vs Peak TOPS Matters
Understanding the distinction between peak and sustained AI performance is critical for several engineering and business reasons:
- Accurate System Sizing and Procurement: Relying solely on peak TOPS can lead to significant over-provisioning of hardware, resulting in wasted capital expenditure and operational costs. Engineers must size systems based on realistic sustained performance requirements.
- Cost and Energy Efficiency: A large gap between peak and sustained performance often indicates inefficient hardware utilization. Optimizing for sustained performance means maximizing the return on investment in silicon and reducing the energy footprint of AI operations.
- Predictable Performance and SLAs: For production deployments, especially in real-time or mission-critical applications, predictable and consistent performance is paramount. Sustained performance provides a reliable baseline for service level agreements (SLAs) and operational planning.
- Architectural Design Decisions: For chip architects, understanding the bottlenecks that limit sustained performance (e.g., memory bandwidth, thermal limits) guides future design choices, pushing innovation in memory subsystems, interconnects, and power management rather than solely focusing on raw arithmetic throughput.
- Software Optimization Focus: Knowledge of sustained performance limitations directs software engineers to focus on optimizations that address real bottlenecks, such as improving data locality, reducing memory transfers, optimizing kernel launch overheads, and efficient batching strategies.
Key Insights for AI Hardware Engineers
For engineers designing AI systems, the Sustained AI Performance vs Peak TOPS gap highlights why real hardware efficiency depends more on memory, power limits, and architecture than raw compute metrics.
- Peak TOPS is a theoretical maximum, representing the raw arithmetic potential, while sustained AI performance is the real-world achievable throughput under operational constraints.
- The primary drivers of the gap are memory bandwidth limitations, power/thermal throttling, and software stack overheads.
- Architectural choices like HBM vs. Unified Memory and specialized compute units profoundly impact the balance between peak and sustained performance.
- Different AI accelerator categories (data center, integrated, consumer, edge) exhibit distinct peak-to-sustained performance ratios due to their specific design priorities and constraints.
- For effective AI system design, deployment, and optimization, engineers must prioritize sustained performance as the critical metric, understanding the underlying silicon-level bottlenecks and making informed tradeoffs.