Summary
This article explains how background AI wake word systems optimize performance-per-watt for always-on voice detection in smart speakers and edge devices. It explores the multi-stage architecture, including ultra-low-power audio front ends, DSP/NPU inference engines, and scratchpad memory that reduce power consumption while maintaining accurate wake word detection.
Table of Contents
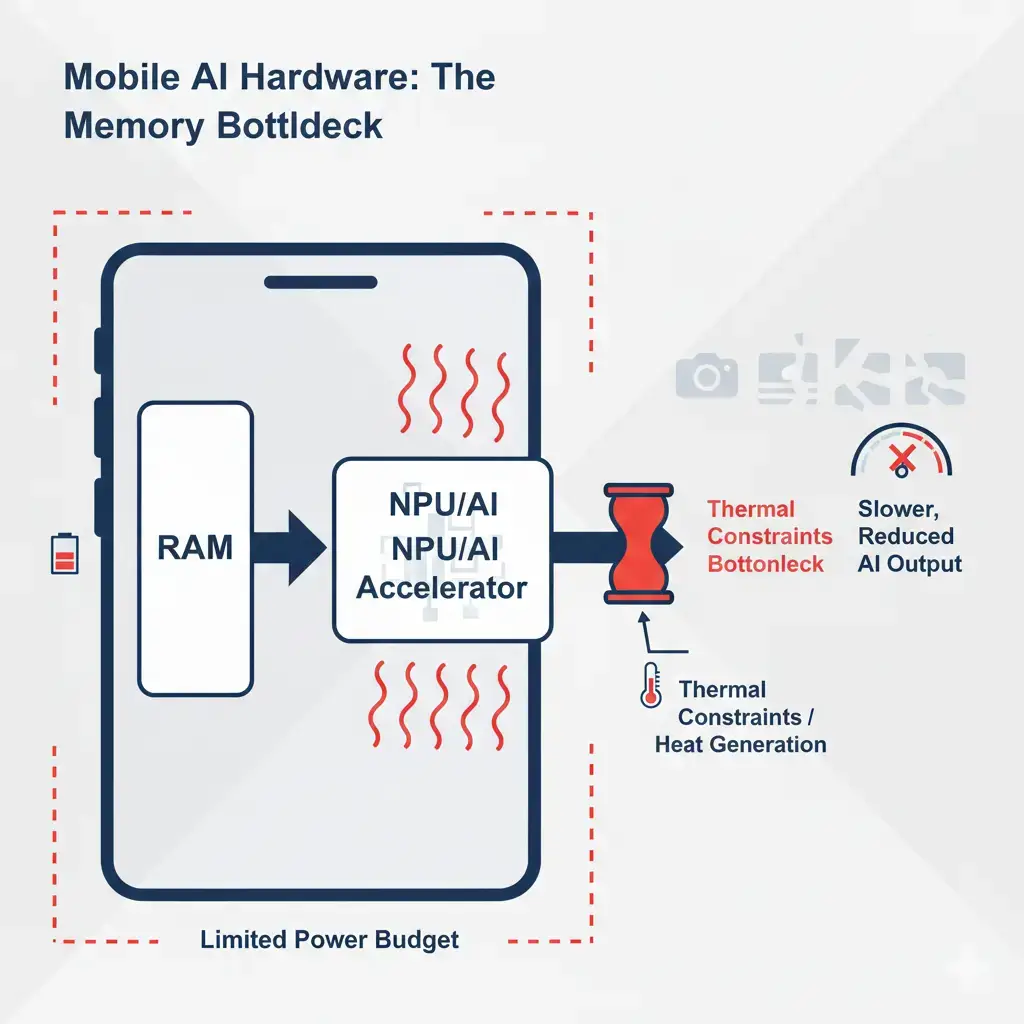
Background AI Wake Word Performance-Per-Watt is a critical engineering challenge driven by the need for continuous, ultra-low-power voice detection. The primary performance bottleneck analysis centers on the memory subsystem, where silicon constraints necessitate a multi-stage, heterogeneous compute architecture heavily reliant on on-chip Scratchpad Memory (SPM). This design minimizes power-intensive off-chip DRAM accesses and cache misses, directly impacting runtime execution efficiency and overall system power consumption for continuous low-power operation.
The proliferation of voice-activated devices necessitates an “always-on” listening capability, enabling natural, hands-free interaction. This seemingly simple user experience, however, presents a formidable engineering problem: how to continuously monitor for a wake word while adhering to stringent power budgets, often measured in milliwatts. This challenge drives a relentless focus on background AI wake word performance-per-watt optimization, where every microjoule consumed by the background AI wake word system is scrutinized. Our analysis will delve into the silicon-level constraints and architectural decisions, with a primary lens on the memory subsystem, that constrain the design space in this domain.
What Is Background AI Wake Word
Background AI Wake Word refers to the continuous, ultra-low-power (ULP) process of monitoring an audio stream for a specific keyword or phrase (e.g., “Hey Google,” “Alexa”). Its core purpose is to act as a trigger, activating the device’s main computational resources only when the wake word is detected. This functionality is fundamental to the user experience of smart speakers, smart displays, wearables, and other voice-enabled IoT devices, allowing them to remain in a deep sleep state until explicitly addressed, thereby significantly extending battery life. The design is a direct consequence of an intractable power budget for continuous, high-fidelity audio processing, necessitating extreme specialization to maintain standby power for extended periods.
How Wake Word Detection Works
Wake word models are typically trained using large voice datasets such as the Google Speech Commands Dataset used in keyword spotting research. The operation of a background AI wake word system is characterized by a multi-stage, heterogeneous compute architecture designed for hierarchical power gating and progressive computational complexity.
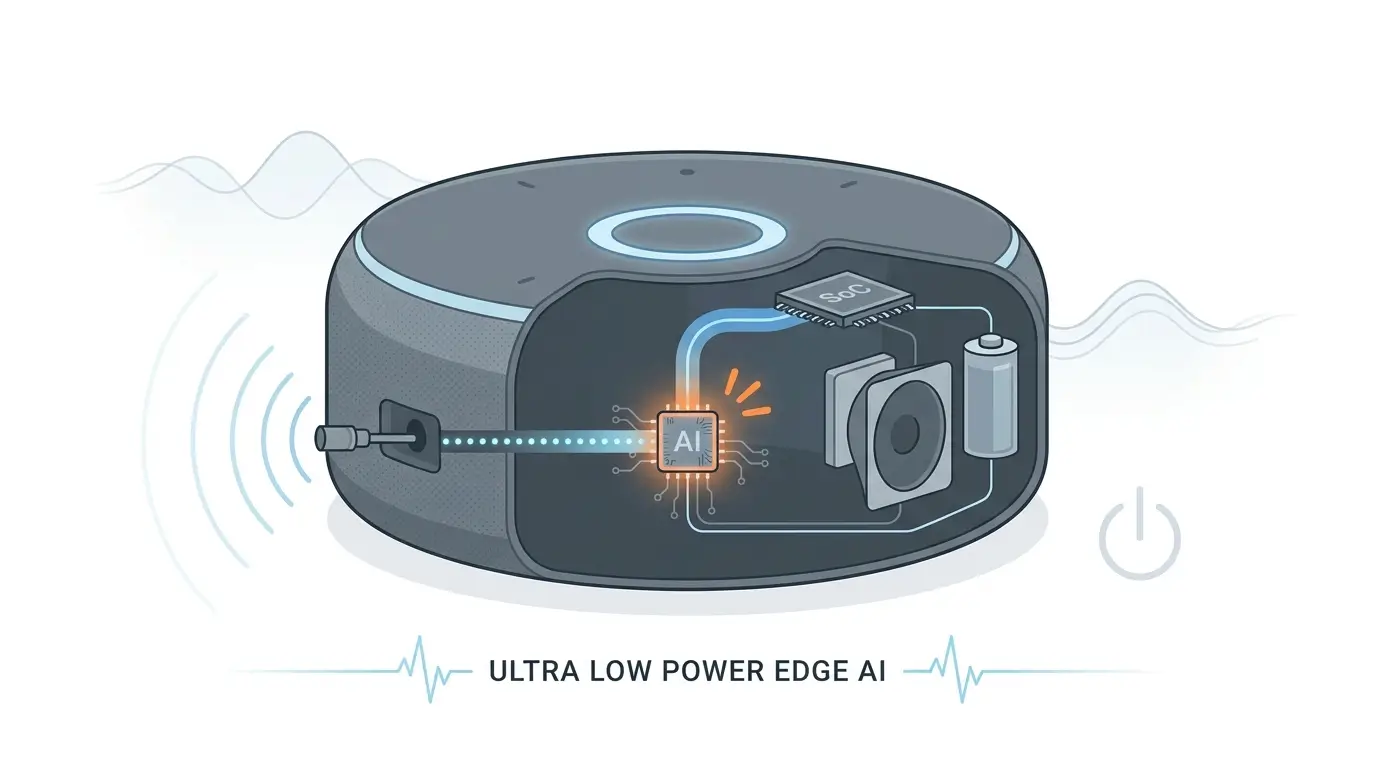
- Ultra-Low-Power Audio Front-End (ULP AFE): This is the “always-on” first stage, consuming the absolute minimum power. It continuously samples audio from the microphone, performs basic signal conditioning (e.g., gain control, noise reduction), and often incorporates a hardware-accelerated Voice Activity Detector (VAD). The ULP AFE typically buffers short audio segments in small, on-chip SRAM or register files, avoiding any off-chip memory access. Its primary role is to detect the presence of speech, not the specific wake word, and to act as the primary gatekeeper for subsequent stages.
- Dedicated NPU/DSP Core: Upon VAD detection by the ULP AFE, this stage is selectively powered up. It runs a highly optimized, often quantized (e.g., INT8, INT4, Binary Neural Network – BNN) neural network model specifically trained for wake word spotting. This model is typically stored entirely within on-chip Scratchpad Memory (SPM) or tightly coupled memory (TCM) to minimize power and latency associated with off-chip DRAM access. The NPU/DSP Core performs the actual keyword inference, and if the wake word is confirmed with high confidence, it triggers the main SoC.
- Main SoC/CPU: This highest-power stage is activated only after the NPU/DSP confirms a wake word. It handles more complex tasks like natural language understanding (NLU), cloud communication, and application execution. Its memory subsystem involves a standard cache hierarchy (L1/L2/L3) and access to off-chip LPDDR/DDR DRAM.

This multi-stage approach ensures that, for the vast majority of the time, only the ULP AFE is active, consuming minimal power. The NPU/DSP operates in a perpetual “burst-and-sleep” cycle, waking up for short, intense inference bursts and immediately returning to deep sleep. The system’s sustained performance is less about raw TOPS and more about the reliability and consistency of this multi-stage triggering mechanism under varying acoustic conditions, directly impacting user experience and responsiveness.
Architecture Overview
This architecture is designed to maximize background AI wake word performance-per-watt in always-on voice systems. Modern edge devices often rely on specialized accelerators such as neural processing units (NPUs) to run wake word inference efficiently on-device. The architecture is fundamentally driven by the imperative to minimize power consumption, particularly within the memory subsystem.
Compute Hierarchy:
- ULP AFE: Comprises analog-to-digital converters (ADCs), digital signal processing (DSP) blocks for filtering/VAD, and a small, ultra-low-power microcontroller (ULP MCU).
- Dedicated NPU/DSP: A specialized hardware accelerator optimized for neural network inference, often with custom instruction sets for MAC operations and activation functions. It includes a tightly coupled local memory for instructions and data.
- Main SoC: A general-purpose application processor (e.g., Arm architecture reference documentation, Cortex-A series) with a rich peripheral set, responsible for high-level system functions.
Memory Subsystem Focus:
The memory architecture is the primary determinant of performance-per-watt.
- Ultra-Low-Power Audio Front-End (ULP AFE) Memory:
- On-chip SRAM/Register Files: Extremely small (kilobytes to tens of kilobytes) for buffering raw audio samples and storing VAD filter coefficients. These are single-cycle access memories, consuming minimal dynamic and static power. No off-chip memory access is permitted at this stage.
- No Cache Hierarchy: The simplicity and low power requirements preclude complex cache structures.
- NPU/DSP Memory:
- Scratchpad Memory (SPM) / Tightly Coupled Memory (TCM): This is the critical memory component for the NPU/DSP. It’s typically a few hundred kilobytes to a few megabytes of dedicated, single-cycle access SRAM. The entire wake word model (weights, biases, activations) must reside within this SPM. This is crucial for performance-per-watt as it avoids higher-latency, higher-power cache misses and off-chip memory accesses. This reliance on SPM creates a rigid model size constraint and complicates model updates, impacting the flexibility of offline execution.
- Small Instruction Cache: Some NPUs/DSPs may include a small instruction cache for frequently executed inference kernels, but data caching is generally avoided in favor of explicit SPM management.
- Direct Memory Access (DMA) Engine: Used to transfer audio frames from the ULP AFE buffer into the NPU/DSP’s SPM for processing, minimizing CPU involvement.
- Main SoC Memory:
- L1/L2/L3 Caches: Standard multi-level cache hierarchy for instruction and data, optimized for general-purpose computing.
- Off-chip LPDDR/DDR DRAM: The main system memory, offering gigabytes of capacity but at significantly higher latency and power consumption compared to on-chip SRAM. Accessed only when the main SoC is fully active.
Power Management:
Sophisticated power-gating, clock-gating, and Dynamic Voltage and Frequency Scaling (DVFS) are implemented across all stages. The multi-stage architecture itself is a hierarchical power-gating strategy, ensuring components are only powered up when their specific computational capability is required.
Performance Characteristics
Optimizing background AI wake word performance-per-watt is essential for battery-powered edge devices. The performance of background AI wake word systems is multifaceted, balancing power efficiency with detection accuracy and responsiveness. Efficient wake word models rely on optimized deep learning inference frameworks designed for low-latency execution on edge hardware.
- Performance-per-Watt (Inferences per Joule): This is the paramount metric. The heavy reliance on on-chip SPM for the NPU/DSP is a direct optimization for this, as SPM offers significantly lower energy per bit access compared to off-chip DRAM. Minimizing off-chip memory transactions is the single most impactful factor in achieving extreme power efficiency during inference bursts.
- Detection Accuracy & Robustness: Measured by False Positive Rate (FPR) and False Negative Rate (FNR). Aggressive quantization (INT8, INT4, BNN) and pruning, while reducing model size and memory footprint (and thus power), inherently introduce a “detection accuracy floor” and increase susceptibility to environmental noise, accents, and distance variations. This directly impacts the user experience and reliability of the device.
- Idle Power Consumption: Dominated by the ULP AFE and its associated minimal memory footprint. This “baseline power draw” is the ultimate target for optimization, as it dictates the long-term standby power budget and, consequently, battery life. Any leakage current in these always-on blocks becomes disproportionately significant.
- Low-Latency Wake Word Detection: User experience demands near-instantaneous response. The fast, deterministic access provided by SPM for model weights and activations is crucial here, as it helps reduce variable cache miss penalties and DRAM access latencies during the critical inference path.
- Model Complexity & Size: Directly constrained by the available on-chip SPM. Larger, more complex models (potentially offering higher accuracy) cannot be deployed without exceeding power budgets or requiring a larger, more power-hungry memory subsystem.
- Memory Bandwidth and Latency: The NPU/DSP requires high bandwidth and low latency to feed its MAC units efficiently during inference bursts. SPM provides this, whereas off-chip DRAM would introduce significant stalls and power overhead.
Real-World Applications
Background AI wake word systems are fundamental enablers for a wide array of modern devices:
- Smart Speakers and Displays: “Alexa,” “Hey Google,” “Siri” activation.
- Smartphones and Tablets: Hands-free voice assistant activation.
- Wearables: Smartwatches, hearables, and fitness trackers increasingly support voice commands, including emerging devices such as AI Smart Rings .
- Automotive Infotainment: Voice control for navigation, media, and climate.
- IoT Devices: Smart home appliances, security cameras, and industrial sensors requiring voice interaction.
In all these applications, the ability to continuously monitor for a wake word without user activation and within strict power envelopes is paramount for user convenience and device autonomy, directly influencing battery impact and sustained performance.
Limitations
Memory constraints often limit improvements in background AI wake word performance-per-watt. Despite significant advancements, several limitations persist, primarily rooted in silicon and memory constraints:
- Rigid On-Chip Memory Constraints: The reliance on SPM, while critical for power, creates a hard limit on model size and complexity. This dictates the maximum neural network capacity, making it challenging to deploy larger, more accurate models or add new wake words without significant re-engineering or compromising other features. This also complicates over-the-air (OTA) model updates, as new models must precisely adhere to pre-allocated SPM regions, impacting offline execution flexibility.
- Detection Accuracy Floor: The aggressive quantization (INT8, INT4, BNN) and pruning necessary to fit models into SPM and reduce power inherently limit the model’s robustness. This leads to an “accuracy floor,” where further training data may yield diminishing returns due to the constrained numerical representation and reduced parameter count, resulting in a higher probability of false negatives or false positives in noisy or varied acoustic environments, thereby affecting sustained performance and user trust.
- Vendor Lock-in: The tight integration of specialized hardware (NPU, DSP, VAD) with highly optimized software stacks and specific memory architectures creates a vertically locked ecosystem. Switching hardware vendors or upgrading NPU generations often requires significant retooling of the software stack, model re-optimization, and potentially re-training, due to dependencies on proprietary SDKs and toolchains.
- Power State Transition Overhead: While the NPU/DSP is mostly idle, frequent wake-ups and sleeps (burst-and-sleep cycle) incur power and latency overheads associated with clock/power gating and DVFS ramp-up/down. Optimizing these transitions is as critical as optimizing inference efficiency, directly impacting overall battery life and latency behavior.
- Environmental Robustness vs. Power: Achieving high accuracy across diverse real-world acoustic conditions (background noise, varying distances, accents) often requires more complex models, which directly conflict with the strict power and memory budgets.
Why It Matters
Improving background AI wake word performance-per-watt enables always-on voice assistants without excessive power consumption. Background AI Wake Word Performance-Per-Watt is not merely an incremental improvement; it is a fundamental enabler for the pervasive adoption of voice as a primary human-computer interface. Without extreme power efficiency, continuous voice interaction would be impractical for battery-powered devices and would significantly increase the standby power consumption of always-plugged-in devices.
The memory subsystem, in particular, is central to this optimization. Its design dictates the trade-offs between model complexity, detection accuracy, latency, and ultimately, the power budget. Innovations in ultra-low-power SRAM, efficient SPM management, and heterogeneous memory architectures directly translate into more capable, responsive, and energy-efficient AI experiences at the edge. This field drives advancements in specialized silicon design, expanding the practical limits for AI inference in highly constrained environments, thereby driving the evolution of ubiquitous, context-aware computing.
Key Takeaways
- Background AI Wake Word relies on a multi-stage, heterogeneous compute architecture designed for extreme power efficiency, primarily through hierarchical power gating.
- The memory subsystem is the primary performance bottleneck and optimization target, with heavy reliance on on-chip Scratchpad Memory (SPM) to avoid power-intensive off-chip DRAM accesses.
- This memory-centric design dictates critical trade-offs between model complexity, detection accuracy, and overall power consumption, leading to an inherent “accuracy floor” due to aggressive quantization.
- Continuous optimization of the ULP AFE’s memory footprint and the NPU/DSP’s SPM utilization is crucial for minimizing idle power and maximizing inferences per joule, directly impacting battery life and sustained performance.
- Addressing these silicon-level memory constraints is vital for enabling natural, hands-free voice interaction in a wide array of power-constrained devices, driving the evolution of edge AI.