Table of Contents
TinyML models run machine learning on ultra-low-power microcontrollers and edge devices, enabling local inference with minimal energy and memory usage. In contrast, large AI models run on powerful hardware such as GPUs or cloud servers, enabling complex reasoning, high accuracy, and advanced AI capabilities. The main difference between TinyML vs Large AI Models lies in their resource requirements, deployment environments, and computational complexity.
Artificial intelligence now runs everywhere—from tiny battery-powered sensors to massive cloud data centers. Choosing the right model architecture is critical because hardware constraints directly affect performance, cost, and power consumption.
When comparing TinyML vs Large AI Models, the difference comes down to resource availability, inference complexity, and deployment environment. TinyML enables ultra-low-power inference on microcontrollers and edge devices, while Large AI models deliver high-accuracy insights using powerful GPUs and cloud infrastructure.
This article explains the architectural, performance, and system-level differences between TinyML and large-scale AI models from an engineering perspective.

What Each Architecture Does
TinyML Models: TinyML models are purpose-built for extreme resource constraints, typically operating within a microwatt power envelope and kilobyte memory footprint. Their primary function is to act as a “silent sentinel,” performing immediate, local pre-processing or simple event detection on raw sensor data. The core value proposition is to eliminate the power and cost associated with data transmission and continuous monitoring.
By making binary decisions (e.g., “motion detected,” “anomaly present”) or extracting minimal features, TinyML avoids waking up more power-hungry systems or transmitting large volumes of raw data to the cloud, thereby enabling ubiquitous, battery-powered, and often disconnected intelligence. This design directly addresses the reality that I/O and communication energy costs frequently dwarf local computation on microcontrollers. Real-device implication: This approach significantly extends battery life in remote sensor deployments, allowing devices to operate for years without maintenance.
Large AI Models: Large AI models are designed for high-complexity, adaptable semantic interpretation, capable of nuanced pattern recognition, complex decision-making, and often, generative tasks. They operate on powerful compute platforms, typically consuming watts to kilowatts of power and utilizing gigabytes to terabytes of memory. Their role is to provide deep insights, dynamic adaptability, and handle complex, evolving tasks that require extensive contextual understanding or generalization across diverse datasets.
These models are the backbone of advanced analytics, natural language processing, computer vision, and recommendation systems, where high accuracy, robustness, and the ability to learn from vast data streams are paramount. Real-device implication: These models enable sustained performance for demanding applications like real-time autonomous driving, where continuous, high-fidelity data processing is critical.
TinyML vs Large AI Models: Architectural Differences
The architectural divergence between TinyML and Large AI models is profound, driven by their disparate resource envelopes and operational objectives.
| Feature | TinyML Models | Large AI Models |
|---|---|---|
| Compute Unit | Microcontrollers (MCUs), specialized µNPUs (e.g., Arm Ethos-U55) | GPUs, TPUs, and high-performance multi-core CPUs |
| Memory Footprint | Kilobytes (KBs) for model weights and activations | Gigabytes (GBs) to Terabytes (TBs) for models and data |
| Power Envelope | Microwatts (µW) to low milliwatts (mW) | Watts (W) to Kilowatts (kW) |
| Runtime Environment | Bare-metal, Real-Time Operating Systems (RTOS) | Complex OS (Linux), containerized environments, hypervisors |
| Scheduling Paradigm | Event-driven, interrupt-based, deterministic bursts, simple priority queues | Multi-threaded/multi-process, OS schedulers (CFS), GPU stream schedulers, resource managers (Kubernetes) |
| Semantic Flexibility | Extreme semantic rigidity; costly re-engineering for changes | High semantic flexibility; adaptable to new patterns with less re-engineering |
| Update Cadence | Infrequent, costly firmware updates (OTA challenging) | Frequent, agile model updates and retraining |
| Security Posture | Limited software security primitives, nascent primitives, and high physical attack vulnerability | Robust software frameworks, a larger attack surface, and less direct physical attack vulnerability |
TinyML’s architecture is characterized by extreme optimization for deterministic simplicity. The “runtime environment” is often just the application itself, tightly coupled to the hardware. This yields ultra-low-latency execution but creates significant semantic rigidity; any change in task or nuanced pattern interpretation often necessitates a complete firmware recompile, re-quantization, and re-flashing. This imposes a “semantic ceiling” that limits dynamic adaptation. Real-device implication: The deterministic nature of TinyML ensures critical safety functions in industrial control systems can execute with guaranteed timing, even in offline scenarios.
Large AI models, conversely, leverage complex hardware and software stacks. Their architecture supports dynamic resource allocation, sophisticated memory management units (MMUs), and often, virtualized environments, enabling high semantic flexibility and the ability to adapt to evolving data distributions with relative ease. These powerful compute platforms often utilize dedicated accelerators (NPU in Smartphones) to handle the intensive computational demands.
Performance Comparison: Critical Runtime Differences
TinyML Models: Runtime scheduling in TinyML is typically event-driven and highly deterministic. The system spends most of its time in deep sleep, consuming microwatts. Upon an external event (e.g., sensor interrupt), the MCU wakes up, executes a short, pre-defined inference burst, and returns to sleep. The focus is on ultra-low wake-up latency and minimal energy per inference cycle.
Throughput for complex, sustained tasks is not a design goal; rather, it’s about efficient, intermittent processing. The execution path is often linear, with minimal OS overhead, leading to predictable, hard real-time performance for its specific, limited task. System bottlenecks are primarily the available on-chip memory (KBs) and the clock cycles required for the inference kernel, which must be carefully profiled to fit within the power budget and meet latency targets. Real-device implication: This design ensures immediate response times for critical alerts, such as a smoke detector activating within milliseconds of detecting an anomaly.
Large AI Models: Runtime scheduling for Large AI models is far more complex, involving multi-core CPUs, multi-GPU systems, and potentially distributed execution. OS schedulers (e.g., Linux CFS) manage CPU threads, while GPU schedulers (e.g., CUDA streams, Multi-Process Service – MPS) orchestrate kernel execution and memory transfers. The objective is to maximize throughput (inferences per second) and minimize average inference latency for complex models.
Bottlenecks are typically memory bandwidth (e.g., HBM, DDR), interconnect bandwidth (e.g., PCIe, NVLink), and the computational intensity of the model. Non-deterministic execution due to OS overhead, resource contention, and dynamic workload balancing is common. For batch inference, latency can be traded for higher throughput, while real-time applications demand low tail latency, often requiring dedicated hardware resources. Real-device implication: In a data center, these models enable thousands of concurrent user queries for generative AI, maintaining acceptable response times despite immense computational load.
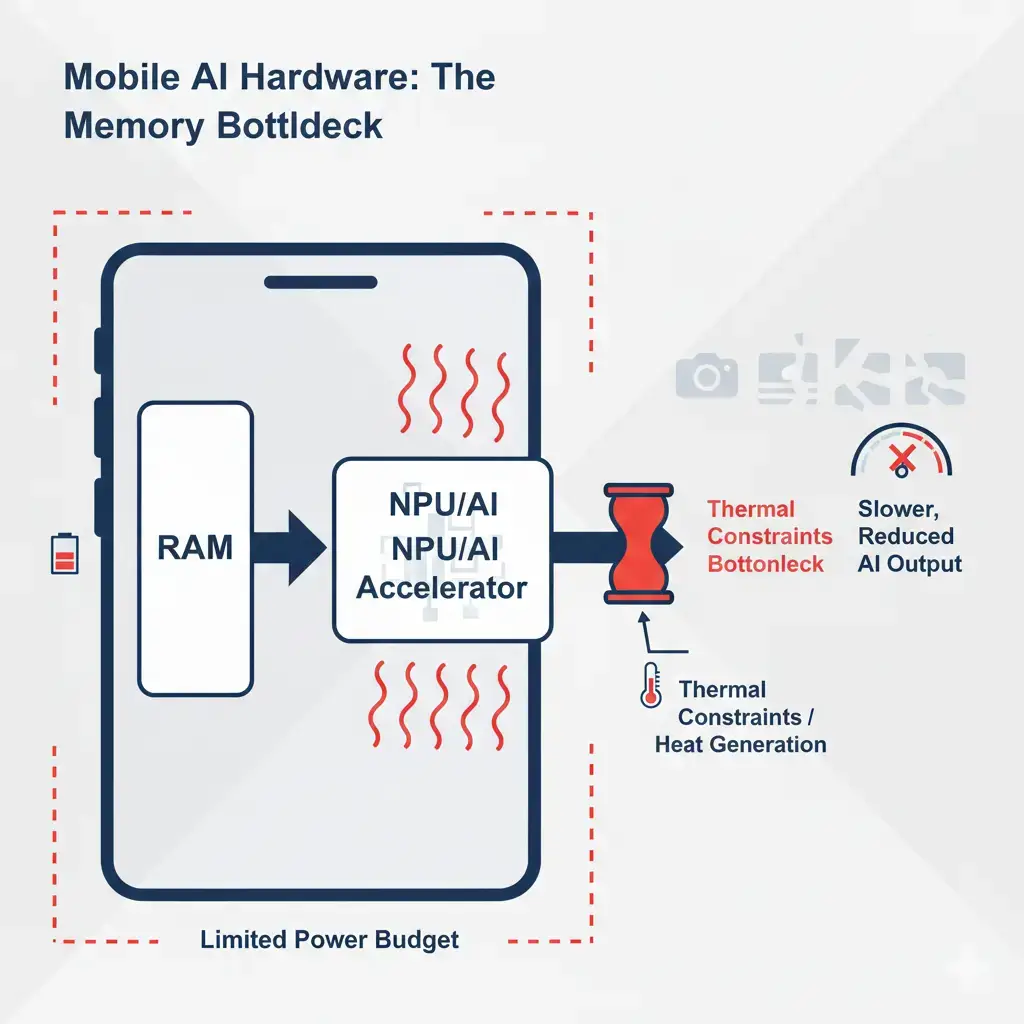
Power and Thermal Differences Between TinyML and Large AI Models
TinyML Models: TinyML’s power profile is defined by its microwatt envelope, achieved through aggressive power gating, deep sleep states, and highly optimized, burst-oriented computation. Devices are designed to be “always-on listening” at sub-milliwatt levels, with inference bursts consuming slightly more power for milliseconds. Due to minimal power dissipation, TinyML devices are inherently thermally stable, ensuring consistent performance over time without throttling.
This characteristic, combined with ultra-low consumption, makes them ideal for energy harvesting solutions, enabling self-sustaining, “install-and-forget” deployments that operate for years without battery replacement. Real-device implication: The inherent thermal stability of TinyML devices allows them to operate reliably in harsh industrial environments or inside sealed enclosures without active cooling.
Large AI Models: Large AI models operate within a power envelope ranging from tens of watts (for edge GPUs) to hundreds or thousands of watts (for data center accelerators). Continuous operation at high utilization generates significant heat, necessitating sophisticated active cooling solutions (fans, liquid cooling). Thermal management is a critical system bottleneck; exceeding thermal design power (TDP) limits leads to clock throttling, which directly degrades performance and introduces non-deterministic latency.
The operational expenditure (OpEx) for power and cooling is a major consideration for large-scale deployments. Real-device implication: Without robust thermal management, a high-end GPU running a large AI model would quickly throttle, leading to a significant drop in sustained performance for tasks like video rendering or scientific simulations.
TinyML vs Large AI Models: Memory and Bandwidth Requirements
TinyML Models: Memory handling in TinyML is characterized by extreme sensitivity to pressure. Models and their activation buffers must fit within kilobytes (KBs) of on-chip SRAM and Flash. External memory is minimal or non-existent. Runtime execution is meticulously designed for streaming or single-pass processing to avoid accumulating intermediate results, preventing stack overflows and performance degradation. Bandwidth requirements are minimal, primarily for sensor data acquisition, which is typically low-rate.
The lack of complex memory hierarchies simplifies runtime but severely limits model complexity. Real-device implication: This constrained memory environment means TinyML devices can perform basic anomaly detection completely offline, without needing to access external storage or cloud resources.
Large AI Models: Large AI models demand vast amounts of memory, ranging from gigabytes to terabytes, typically utilizing high-bandwidth memory (HBM) on GPUs and large capacities of DDR DRAM. Memory bandwidth is a primary system bottleneck, as model weights, activations, and input/output data must be rapidly moved between compute units and memory.
Complex memory hierarchies (L1/L2 caches, shared memory, HBM, main DRAM) are crucial for performance. Interconnect bandwidth (e.g., PCIe, NVLink, Ethernet for distributed systems) is also critical for data transfer between accelerators, CPUs, and storage, directly impacting runtime efficiency and scalability. Tools like the NVIDIA TensorRT documentation highlight techniques for optimizing model deployment to manage these memory and bandwidth demands. Real-device implication: Insufficient memory bandwidth in a large AI system can lead to “data starvation” for the compute units, severely limiting the sustained performance of complex models like large language models.
Software Ecosystem & Tooling
TinyML Models: The software ecosystem for TinyML is still nascent and fragmented. Development often involves low-level C/C++ programming, assembly, and specialized, often vendor-specific, toolchains. Abstraction layers are minimal or non-existent to conserve resources. This results in a “debuggability tax,” where debugging complex ML models on constrained hardware, without rich OS features or standard debugging tools, becomes a monumental task.
This significantly slows development velocity and raises the barrier to entry, despite efforts from frameworks like TensorFlow Lite Micro. Real-device implication: The complexity of TinyML development often means that firmware updates for deployed devices are infrequent and costly, impacting the ability to quickly patch vulnerabilities or add new features.
Large AI Models: Large AI models benefit from a mature and rich software ecosystem. High-level frameworks like TensorFlow, PyTorch, and JAX provide extensive APIs, abstraction layers, and robust debugging environments. Comprehensive libraries (e.g., CUDA, OpenCL, cuDNN) optimize low-level operations. The tooling supports rapid prototyping, distributed training, model versioning, and deployment across diverse platforms, significantly accelerating development cycles and fostering a vibrant community. Real-device implication: This robust ecosystem enables rapid iteration and deployment of new features in cloud-based AI services, allowing companies to quickly respond to market demands or improve model accuracy.
TinyML vs Large AI Models: Real-World Deployment
TinyML Models: TinyML models are deployed in ubiquitous, battery-powered, and often disconnected edge devices. Examples include smart sensors in industrial IoT, wearables for health monitoring, predictive maintenance in machinery, and environmental monitoring. Updates are infrequent and costly, often requiring over-the-air (OTA) firmware updates that are challenging to implement robustly on constrained devices.
Data handling involves local pre-processing and minimal data transmission (e.g., binary decisions or extracted features). The primary security focus is on physical device security, as direct access can expose model weights or sensor data due to less mature software security primitives. These devices are often considered “disposable” due to their low cost and pervasive integration. Real-device implication: The ability of TinyML devices to operate completely offline is crucial for security and privacy in sensitive applications, such as personal health monitoring, where data never leaves the device.
Large AI Models: Large AI models are typically deployed in cloud data centers, powerful edge servers, or high-end consumer devices (e.g., smartphones, autonomous vehicles). They require continuous network access for data ingestion, model updates, and often, distributed inference. Update cycles are frequent and agile, allowing for rapid model retraining and deployment to adapt to new data or evolving requirements.
Data handling involves extensive collection, transmission, and cloud-based processing. Security focuses on software vulnerability management, data privacy, and robust network security, given the larger software attack surface and sensitive data handling. The deployment strategy for these models often involves a blend of local and remote processing, falling under the umbrella of Edge AI Vs Hybrid AI Vs Cloud AI. Real-device implication: For autonomous vehicles, the need for continuous model updates and vast data processing means these systems rely heavily on robust connectivity and powerful on-board compute, impacting overall system cost and power consumption.
Which Design Is More Efficient
The concept of “efficiency” is context-dependent.
TinyML models are more efficient when the primary objective is ultra-low-power, always-on local event detection or pre-processing, where the cost of data transmission (power, bandwidth, latency) to a more powerful system is the dominant bottleneck. Their efficiency stems from avoiding computation and communication by performing minimal, highly targeted inference at the source.
For tasks within their “semantic ceiling”—simple pattern recognition, anomaly detection, keyword spotting—they offer unparalleled energy efficiency and enable pervasive intelligence in environments where larger systems are infeasible due to power, cost, or connectivity constraints. Real-device implication: For a smart doorbell, a TinyML model efficiently detects human presence, minimizing false positives and significantly extending battery life by only activating the main camera and network when truly necessary.
Large AI models are more efficient when the task demands high accuracy, complex semantic understanding, generalization across diverse data, and dynamic adaptability. Their efficiency is measured by the quality of insights, the breadth of tasks they can perform, and the speed of iteration on complex problems. While consuming significantly more power and resources, the value derived from their advanced capabilities (e.g., nuanced medical diagnosis, real-time autonomous navigation, sophisticated content generation) justifies the operational expenditure. They are efficient in maximizing computational output per unit of time for highly complex, data-intensive workloads. Real-device implication: In medical imaging, a large AI model efficiently processes high-resolution scans to identify subtle anomalies, providing critical diagnostic accuracy that far outweighs its power consumption in a clinical setting.
The choice between TinyML vs Large AI Models is not about one being universally superior, but about selecting the architecture that is most efficient for the specific problem’s constraints, value proposition, and acceptable trade-offs in capability versus resource consumption.
Key Takeaways
- Resource Envelope Dictates Design: TinyML operates within microwatt/kilobyte constraints for local, event-driven tasks, while Large AI leverages high-power/gigabyte resources for complex, adaptable inference.
- Runtime Scheduling Divergence: TinyML employs deterministic, burst-oriented execution with minimal OS overhead, prioritizing wake-up latency and energy per inference. Large AI uses complex OS and GPU schedulers for throughput, managing multi-threaded, non-deterministic workloads.
- Semantic Rigidity vs. Flexibility: TinyML’s extreme optimization leads to semantic rigidity and costly re-engineering for model changes. Large AI offers high semantic flexibility and agile adaptation.
- Bottlenecks & Efficiency: TinyML’s primary bottlenecks are memory and re-engineering costs, with efficiency derived from avoiding data transmission. Large AI’s bottlenecks are memory bandwidth, interconnects, and thermal management, with efficiency tied to maximizing complex computational output.
- Deployment & Security: TinyML enables pervasive, disconnected, physically vulnerable deployments. Large AI supports cloud/edge server deployments with robust software security, requiring continuous connectivity.
Frequently Asked Questions (FAQs)
What is TinyML used for?
TinyML is used for running machine learning models on microcontrollers and low-power embedded devices such as IoT sensors and wearables.
Are large AI models used at the edge?
Some optimized versions run on edge GPUs or NPUs, but most large AI models operate in cloud or data center environments.
Is TinyML faster than large AI models?
TinyML can deliver faster responses for simple tasks because inference happens locally without cloud communication.